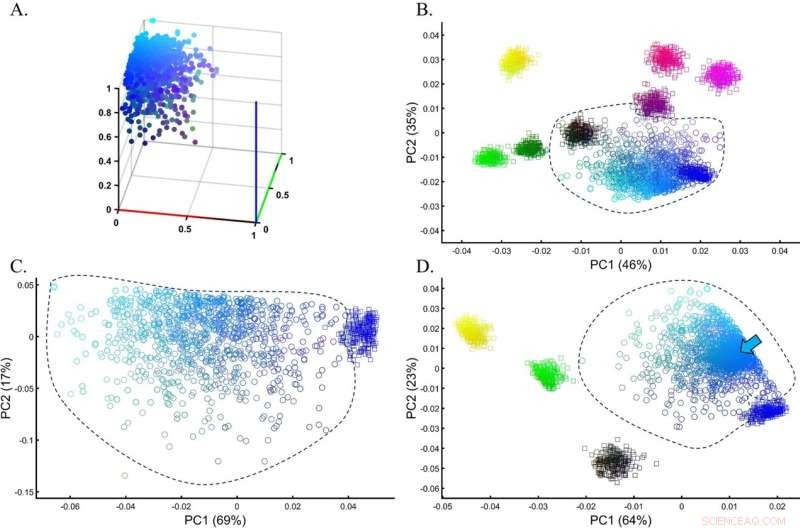
Utvärdering av noggrannheten av PCA-klustring för en heterogen testpopulation i en simulering av en GWAS-inställning. (A) Den sanna fördelningen av testcyanpopulationen (n = 1000). (B) PCA för testpopulationen med åtta jämnstora (n = 250) prover från referenspopulationer. (C) PCA för testpopulationen med blått från den tidigare analysen visar en minimal överlappning mellan kohorterna. (D) PCA för testpopulationen med fem jämnstora (n = 250) prover från referenspopulationer, inklusive cyan (markerad med en pil). Färger (B) uppifrån och ned och från vänster till höger inkluderar:gul [1,1,0], ljusröd [1,0,0,5], lila [1,0,1], mörklila [0,5,0,0,5] ], svart [0,0,0], mörkgrön [0,0,5,0], grön [0,1,0] och blå [1,0,0]. Kredit:Scientific Reports (2022). DOI:10.1038/s41598-022-14395-4
Den vanligaste analysmetoden inom populationsgenetik är djupt bristfällig, enligt en ny studie från Lunds universitet i Sverige. Detta kan ha lett till felaktiga resultat och missuppfattningar om etnicitet och genetiska samband. Metoden har använts i hundratusentals studier, vilket påverkar resultat inom medicinsk genetik och även kommersiella härkomsttester. Studien publiceras i Scientific Reports .
Hastigheten med vilken vetenskaplig data kan samlas in ökar exponentiellt, vilket leder till massiva och mycket komplexa datauppsättningar, kallade "Big Data-revolutionen". För att göra dessa data mer hanterbara använder forskare statistiska metoder som syftar till att komprimera och förenkla data samtidigt som de behåller det mesta av nyckelinformationen. Den kanske mest använda metoden kallas PCA (principal component analysis). I analogi, tänk på PCA som en ugn med mjöl, socker och ägg som indata. Ugnen kan alltid göra samma sak, men resultatet, en kaka, beror helt på ingrediensernas förhållande och hur de kombineras.
"Det förväntas att den här metoden kommer att ge korrekta resultat eftersom den används så ofta. Men den är varken en garanti för tillförlitlighet eller ger statistiskt robusta slutsatser", säger Dr. Eran Elhaik, docent i molekylär cellbiologi vid Lunds universitet.
Enligt Elhaik bidrog metoden till att skapa gamla uppfattningar om ras och etnicitet. Det spelar en roll i tillverkningen av historiska berättelser om vem och var människor kommer ifrån, inte bara av det vetenskapliga samfundet utan också av kommersiella företag. Ett berömt exempel är när en framstående amerikansk politiker gjorde ett härkomsttest före presidentkampanjen 2020 för att stödja sina förfäders anspråk. Ett annat exempel är missuppfattningen av ashkenaziska judar som en ras eller en isolerad grupp som drivs av PCA-resultat.
"Denna studie visar att dessa resultat var opålitliga", säger Eran Elhaik.
PCA används inom många vetenskapliga områden, men Elhaiks studie fokuserar på dess användning i populationsgenetik, där explosionen i datauppsättningsstorlekar är särskilt akut, vilket drivs av de minskade kostnaderna för DNA-sekvensering.
Området paleogenomics, där vi vill lära oss om forntida folk och individer såsom kopparåldern européer, är starkt beroende av PCA. PCA används för att skapa en genetisk karta som placerar det okända provet tillsammans med kända referensprover. Hittills har de okända proven antagits vara relaterade till vilken referenspopulation de överlappar eller ligger närmast på kartan.
Emellertid upptäckte Elhaik att det okända urvalet kunde fås att ligga nära praktiskt taget vilken referenspopulation som helst bara genom att ändra antalet och typerna av referensproverna, generera praktiskt taget oändliga historiska versioner, alla matematiskt "korrekta", men bara en kan vara biologiskt korrekt .
I studien har Elhaik undersökt de tolv vanligaste populationsgenetiska tillämpningarna av PCA. Han har använt både simulerade och verkliga genetiska data för att visa hur flexibla PCA-resultat kan vara. Enligt Elhaik innebär denna flexibilitet att slutsatser baserade på PCA inte kan litas på eftersom varje ändring av referensen eller testproverna kommer att ge andra resultat.
Mellan 32 000 och 216 000 vetenskapliga artiklar enbart inom genetik har använt PCA för att utforska och visualisera likheter och skillnader mellan individer och populationer och baserat sina slutsatser på dessa resultat.
"Jag tror att dessa resultat måste omvärderas", säger Elhaik.
Han hoppas att den nya studien ska utveckla ett bättre förhållningssätt för att ifrågasätta resultat och därmed bidra till att göra vetenskapen mer tillförlitlig. Han tillbringade en betydande del av det senaste decenniet med att banbryta sådana metoder, som den geografiska populationsstrukturen (GPS), för att förutsäga biogeografi från DNA, och Pairwise Matcher, som förbättrar fallkontrollmatchningar som används i genetiska tester och läkemedelsprövningar.
"Tekniker som erbjuder sådan flexibilitet uppmuntrar dålig vetenskap och är särskilt farliga i en värld där det finns ett intensivt tryck att publicera. Om en forskare kör PCA flera gånger kommer frestelsen alltid att vara att välja den produktion som ger den bästa historien", tillägger Prof. William Amos, från University of Cambridge, som inte var involverad i studien. + Utforska vidare