Vi är beroende av katalysatorer för att omvandla vår mjölk till yoghurt, för att producera Post-It-lappar från pappersmassa och för att låsa upp förnybara energikällor som biobränslen. Att hitta optimala katalysatormaterial för specifika reaktioner kräver mödosamma experiment och beräkningsintensiva kvantkemiberäkningar.
Ofta vänder sig forskare till grafiska neurala nätverk (GNN) för att fånga och förutsäga atomsystemens strukturella intrikata, ett effektivt system först efter att den noggranna omvandlingen av 3D-atomstrukturer till exakta rumsliga koordinater på grafen är klar.
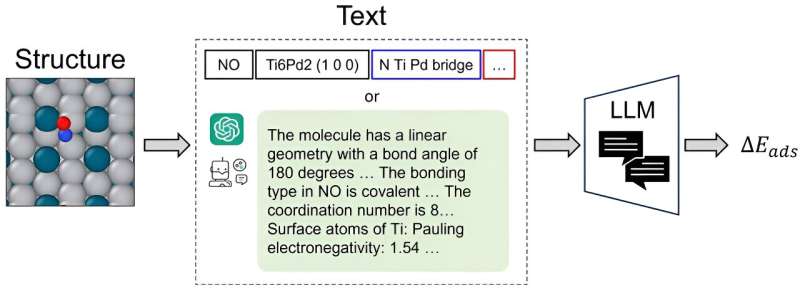
CatBERTa, en transformatormodell för energiförutsägelse, utvecklades av forskare vid Carnegie Mellon Universitys College of Engineering som ett tillvägagångssätt för att tackla förutsägelse av molekylära egenskaper med hjälp av maskininlärning.
"Detta är det första tillvägagångssättet som använder en stor språkmodell (LLM) för denna uppgift, så vi öppnar upp en ny väg för modellering", säger Janghoon Ock, Ph.D. kandidat i Amir Barati Farimanis labb.
En viktig differentiator är modellens förmåga att direkt använda text (naturligt språk) utan någon förbearbetning för att förutsäga egenskaperna hos adsorbat-katalysatorsystemet. Denna metod är särskilt fördelaktig eftersom den förblir lätt att tolka av människor, vilket gör att forskare kan integrera observerbara egenskaper i sina data sömlöst.
Att tillämpa transformatormodellen i sin forskning ger dessutom betydande insikter. Särskilt självuppmärksamhetspoängen är avgörande för att förbättra deras förståelse av tolkningsbarhet inom denna ram.
"Jag kan inte säga att det kommer att vara ett alternativ till state-of-the-art GNN, men vi kanske kan använda det här som ett komplement", sa Ock. "Som man säger:'Ju fler desto roligare'."
Modellen levererar prediktiv noggrannhet jämförbar med den som uppnåtts av tidigare versioner av GNN. Noterbart var CatBERTa mer framgångsrik när den tränades på datauppsättningar av begränsad storlek. Dessutom har CatBERTa överträffat förmågan att avbryta fel hos befintliga GNN.
Teamet fokuserade på adsorptionsenergi men sa att tillvägagångssättet kan utvidgas till andra egenskaper, såsom HOMO-LUMO-gapet och stabiliteter relaterade till adsorbat-katalysatorsystem, givet en lämplig datauppsättning.
Genom att integrera kapaciteten hos omfattande språkmodeller med kraven på katalysatorupptäckt, strävar teamet efter att effektivisera processen för effektiv katalysatorscreening. Ock arbetar med att förbättra modellens noggrannhet.
Resultaten publiceras i tidskriften ACS Catalysis .
Mer information: Janghoon Ock et al, Catalyst Energy Prediction with CatBERTa:Unveiling Feature Exploration Strategies through Large Language Models, ACS Catalysis (2023). DOI:10.1021/acscatal.3c04956
Journalinformation: ACS-katalys
Tillhandahålls av Carnegie Mellon University Mechanical Engineering