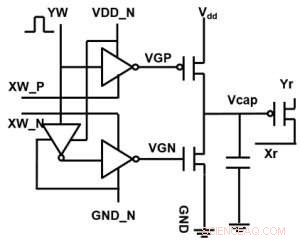
Figur 1. Schematisk enhetscell för en kondensatorbaserad korspunktsmatris. Kredit:IBM
IBM når bortom digital teknik med en kondensatorbaserad korspunktsuppsättning för analoga neurala nätverk, uppvisar potentiella förbättringar av storleksordningar i djupinlärningsberäkningar. Analoga datorarkitekturer utnyttjar lagringskapaciteten och fysiska egenskaper hos vissa minnesenheter, inte bara för att lagra information, men också för att utföra beräkningar. Detta har potential att avsevärt minska den tid och energi som datorer kräver eftersom data inte behöver flyttas mellan minnet och processorn. Nackdelen kan vara en minskning av beräkningsnoggrannheten, men för system som inte kräver hög noggrannhet, det är rätt avvägning.
I analoga neurala nätverk (NN), icke-flyktigt minne (NVM) baserade korspunktsmatriser har uppnått lovande resultat för slutledningsuppgifter. Dock, Att träna NN till hög noggrannhet är svårt för NVM-enheter, eftersom framgångsrik träning är beroende av att hålla de inkrementella förändringarna i NN-vikt små (kräver ungefär 1, 000 uppdateringstillstånd) och symmetriska (så att positiva och negativa uppdateringar balanserar i genomsnitt). Sådana problem kan lösas genom att använda kondensatorer. Eftersom laddning kan adderas eller subtraheras kontinuerligt om antalet elektroner är högt, analog och symmetrisk viktuppdatering kan uppnås. Vi presenterade en kondensatorbaserad korspunktsmatris för analoga neurala nätverk vid 2018 VLSI Technology Symposium. Den nya arkitekturen uppnådde rekordsymmetri och linjäritet för viktuppdatering.
Figur 1 visar enhetscellschemat för en kondensatorbaserad korspunktsmatris. Nyckelkomponenten är kondensatorn som är ansluten till en utläsningsfälteffekttransistor (FET). Laddningen på kondensatorn representerar den synaptiska vikten och kondensatorn laddas och urladdas med två strömkälla FET. Figur 2 visar den uppmätta förändringen i konduktansen för avläsnings-FET för en enskild cell, respektive motsvarande kondensatorspänning, genom att tillämpa tio cykler med 400 positiva uppdateringar följt av 400 negativa uppdateringar. Figur 3 jämför de experimentella icke-linjäritetsuppdateringsfaktorerna för vår kondensatorbaserade analoga synaps med andra NVM-teknologier. Den kondensatorbaserade enhetscellen ger den bästa symmetri och linjäritet som visats hittills. Figur 4 visar parallell viktuppdatering på en 2×2-matris.
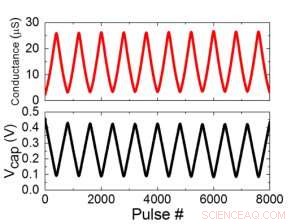
Figur 2. (a) Experimentella resultat för uppdatering av encell med 8000 pulser. (b) Motsvarande kondensatorspänningsändring. Pulsbredd 50 ns, period:500 ns. Kredit:IBM
Även om kondensatorer är flyktiga, läckaget kan kompenseras under viktuppdatering. Eftersom träningen upprepade gånger går framåt, bakåt- och viktuppdateringscykler, vikter efter förfall i föregående cykel används i träning för nästa cykel och uppdateras. Därför, inga avsiktliga uppdateringscykler behövs. Vi testade effekten av retentionstid på träning, med ett helt uppkopplat nätverk. Den har ett indatalager, två dolda lager, och ett utdatalager (Figur 5) och tränades på MNIST-datauppsättningen genom stokastisk gradientnedstigning och backpropagation. Om man antar att träningscykelns längd per lager (framåt+bakåt+uppdatering) är 200 ns och den synaptiska vikten avtar med RC-tidskonstant τ, vi fann att straff i träningsnoggrannhet på grund av kondensatorladdningsförlust blir försumbar när τ> 106 × träningscykelns längd (Figur 6). Vi testade också kravet på retentionstid för ett konvolutionellt nätverk. Vårt testnätverk har två faltningslager med två poollager och två helt anslutna lager (Figur 7). På grund av viktdelningen (återanvändningen) i konvolutionerande lager, retentionskraven för ett konvolutionellt neuralt nätverk (CNN) är cirka 600 större (Figur 8).
Vi uppskattar skalbarheten för denna kondensatorbaserade array som en funktion av läckage för både fullt anslutna och konvolutionella neurala nätverk (Figur 9). Cirkeldatapunkter visar att kondensatorn skalas linjärt med passtransistorläckage. Fyrkantiga datapunkter visar att när läckaget är stort, cellområdet domineras av kondensatorerna; när läckströmmen är liten, området kommer att domineras av FET i cellen. För DRAM-teknik med läckage på 1 fA/cell krävs kondensator <1fF/cell för fullt anslutet neuralt nätverk och ~ 100 fF/cell för CNN. Skalbarheten till större input och fler lager behöver studeras ytterligare. Även om den kan behöva större kondensator när ingången blir större, våra preliminära resultat (kommer att publiceras) visar att nätverks-/algoritmoptimering kan minska kondensatorbehovet.
IBM arbetar nu med ett nytt idealminne med optimerat analogt beteende. Dessa kondensatorer gör att analog AI-kärna kan implementeras på ett accelererat schema, eftersom tekniken och processen är tillgänglig.
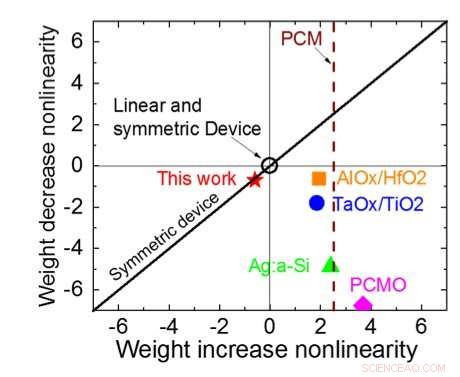
Figur 3. Konduktans-olinjäritet för detta arbete jämfört med andra NVM-teknologier. Kredit:IBM
Förutom vår kondensatormetod, IBM undersöker andra nya element för analogt minne och beräkning som fasförändringsminne (PCM) och resistivt RAM (RRAM). Dessa element varierar med avseende på cellområden, bibehållande, symmetri, och mognad. Analoga acceleratorer är en komponent i IBM Research AI:s pipeline av AI-hårdvaruacceleratorer. Pipelinen börjar med att få ut det mesta av befintliga GPU-acceleratorer, följt av innovativa digitala AI-kärnor som utnyttjar ungefärlig beräkning.
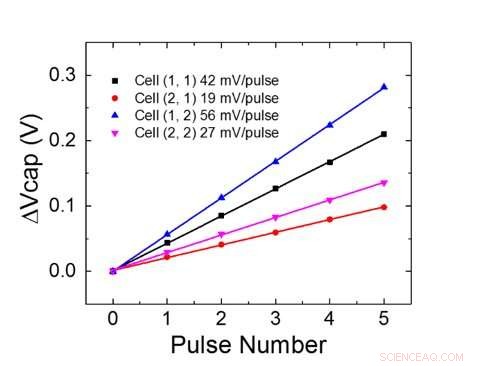
Figur 4. Parallell viktuppdatering på en 2×2 array. Kredit:IBM
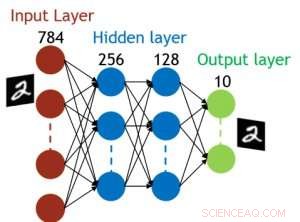
Figur 5. Simulerad struktur för fullt anslutet neuralt nätverk. Kredit:IBM
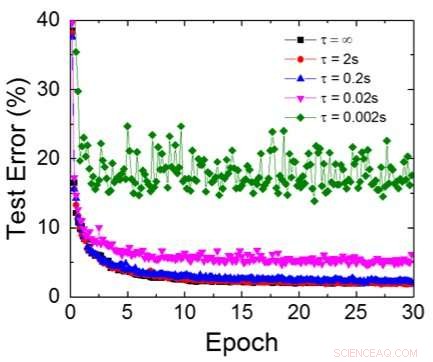
Figur 6. Simulerat testfel för MNIST-datauppsättning, antar att vikter avtar kontinuerligt med olika RC-tidskonstanter τ, 200ns träningscykellängd. Kredit:IBM
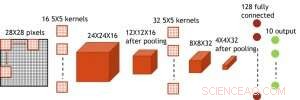
Figur 7. Simulerad struktur för faltningsneurala nätverk. Kredit:IBM
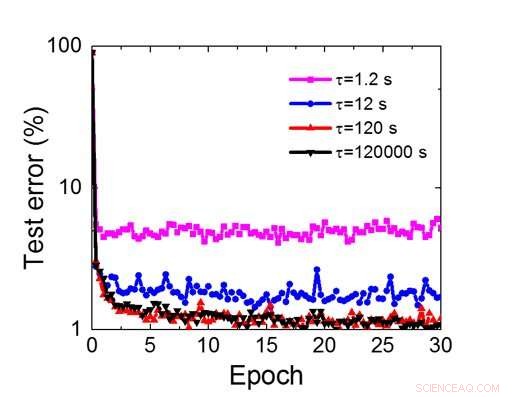
Figur 8. Simulerat retentionstidskrav för denna kondensatorbaserade array för att träna faltningsneurala nätverk. Kredit:IBM
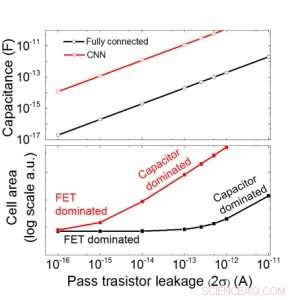
Figur 9. Skalbarhet för denna kondensatorbaserade array som en funktion av läckage för både fullt anslutna och konvolutionerande neurala nätverk. Kredit:IBM