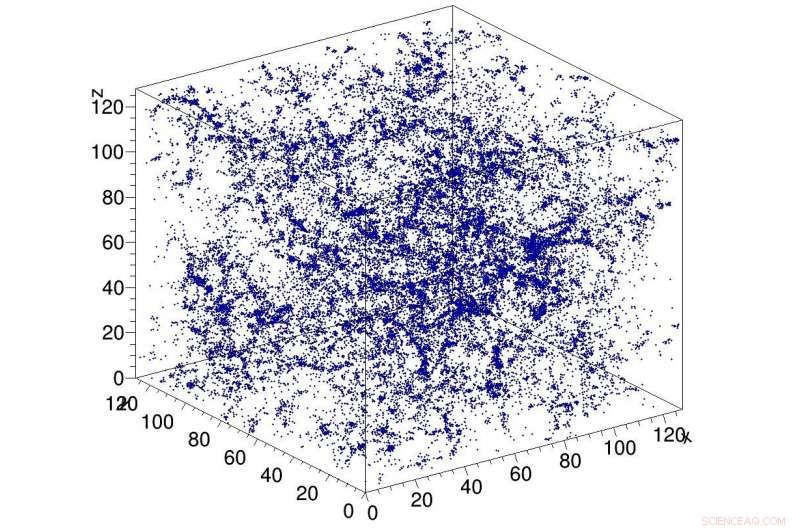
Exempel på simulering av mörk materia i universum, används som input till CosmoFlow-nätverket. CosmoFlow är den första storskaliga vetenskapsapplikationen som använder TensorFlow-ramverket på en CPU-baserad högpresterande datorplattform med synkron träning. Kredit:Lawrence Berkeley National Laboratory
Ett Big Data Center-samarbete mellan beräkningsforskare vid Lawrence Berkeley National Laboratorys (Berkeley Lab) National Energy Research Scientific Computing Center (NERSC) och ingenjörer vid Intel och Cray har gett ytterligare ett första steg i strävan att tillämpa djupinlärning på dataintensiv vetenskap:CosmoFlow , den första storskaliga vetenskapsapplikationen som använder TensorFlow-ramverket på en CPU-baserad högpresterande datorplattform med synkron träning. Det är också den första att bearbeta tredimensionella (3-D) rumsliga datavolymer i denna skala, ger forskare en helt ny plattform för att få en djupare förståelse av universum.
Kosmologiska ''big data''-problem går utöver den enkla mängden data som lagras på disken. Observationer av universum är nödvändigtvis ändliga, och utmaningen som forskarna står inför är hur man kan utvinna mest information från de observationer och simuleringar som finns tillgängliga. Sammansättningen av problemet är att kosmologer typiskt karakteriserar materiens fördelning i universum med hjälp av statistiska mått på materiens struktur i form av två- eller trepunktsfunktioner eller annan reducerad statistik. Metoder som djupinlärning som kan fånga alla funktioner i materiens distribution skulle ge större insikt om mörk energis natur. De första som insåg att djupinlärning kunde tillämpas på detta problem var Siamak Ravanbakhsh och hans kollegor, som det hänvisas till i den 33:e internationella konferensen om maskininlärning. Dock, beräkningsflaskhalsar vid uppskalning av nätverk och datauppsättning begränsade omfattningen av problemet som kunde åtgärdas.
Motiverad att ta itu med dessa utmaningar, CosmoFlow designades för att vara mycket skalbar; att bearbeta stora, 3-D kosmologidatauppsättningar; och att förbättra prestanda för djupinlärning på moderna HPC-superdatorer som den Intel-processorbaserade superdatorn Cray XC40 Cori på NERSC. CosmoFlow är byggt ovanpå det populära TensorFlow-ramverket för maskininlärning och använder Python som frontend. Applikationen använder Cray PE Machine Learning Plugin för att uppnå oöverträffad skalning av TensorFlow Deep Learning-ramverket till mer än 8, 000 noder. Den drar också nytta av Crays DataWarp I/O-acceleratorteknologi, som ger den I/O-genomströmning som krävs för att nå denna nivå av skalbarhet.
I ett tekniskt dokument som ska presenteras på SC18 i november, CosmoFlow-teamet beskriver applikationen och de första experimenten med N-kroppssimuleringar av mörk materia som producerats med MUSIC och pycola-paketen på Coris superdator vid NERSC. I en serie av skalningsexperiment med en nod och flera noder, teamet kunde demonstrera helt synkron dataparallell träning den 8, 192 av Cori med 77 % parallell effektivitet och 3,5 Pflop/s ihållande prestanda.
"Vårt mål var att visa att TensorFlow kan köras i skala på flera noder effektivt, sa Deborah Bard, en big data-arkitekt vid NERSC och en medförfattare till det tekniska dokumentet. "Såvitt vi känner till, detta är den största implementeringen någonsin av TensorFlow på processorer, och vi tror att det är det största försöket att köra TensorFlow på det största antalet CPU-noder."
Tidigt på, CosmoFlow-teamet satte upp tre primära mål för detta projekt:vetenskap, enkelnodsoptimering och skalning. Det vetenskapliga målet var att visa att djupinlärning kan användas på 3D-volymer för att lära sig universums fysik. Teamet ville också säkerställa att TensorFlow körde effektivt och effektivt på en enda Intel Xeon Phi-processornod med 3D-volymer, som är vanliga inom vetenskapen men inte så mycket inom industrin, där de flesta djupinlärningsapplikationer handlar om 2D-bilddatauppsättningar. Och slutligen, säkerställa hög effektivitet och prestanda när den skalas över 1000-tals noder på Coris superdatorsystem.
Som Joe Curley, Senior direktör för kodmoderniseringsorganisationen i Intels datacentergrupp, noterade, "Big Data Center-samarbetet har gett fantastiska resultat inom datavetenskap genom kombinationen av Intel-teknik och dedikerade programvaruoptimeringsinsatser. Under CosmoFlow-projektet, vi identifierade ramar, kärna och kommunikationsoptimering som ledde till mer än 750x prestandaökning för en enda nod. Lika imponerande, teamet löste problem som begränsade skalningen av tekniker för djupinlärning till 128 till 256 noder – för att nu tillåta CosmoFlow-applikationen att skala effektivt till 8, 192 noder av Cori-superdatorn på NERSC."
"Vi är glada över resultaten och genombrotten i tillämpningar för artificiell intelligens från detta samarbetsprojekt med NERSC och Intel, sa Per Nyberg, vice VD för marknadsutveckling, artificiell intelligens och moln på Cray. "Det är spännande att se CosmoFlow-teamet dra nytta av unik Cray-teknik och utnyttja kraften i en Cray-superdator för att effektivt skala modeller för djupinlärning. Det är ett bra exempel på vad många av våra kunder strävar efter när det gäller att konvergera traditionell modellering och simulering med nya djupinlärnings- och analysalgoritmer, allt på en singel, skalbar plattform."
Prabhat, Gruppledare för data- och analystjänster på NERSC, Lagt till, "Från mitt perspektiv, CosmoFlow är ett föredömligt projekt för Big Data Center-samarbetet. Vi har verkligen utnyttjat kompetens från olika institutioner för att lösa ett svårt vetenskapligt problem och förbättra vår produktionsstapel, som kan gynna den bredare NERSC-användargemenskapen."
Förutom Bard och Prabhat, medförfattare på SC18-papperet inkluderar Amrita Mathuriya, Lawrence Meadows, Lei Shao, Tuomas Karna, John Pennycook, Jason Sewall, Nalini Kumar och Victor Lee från Intel; Peter Mendygral, Diana Moise, Kristyn Maschhoff och Michael Ringenburg från Cray; Siyu He och Shirley Ho från Flatiron Institute; och James Arnemann från UC Berkeley.