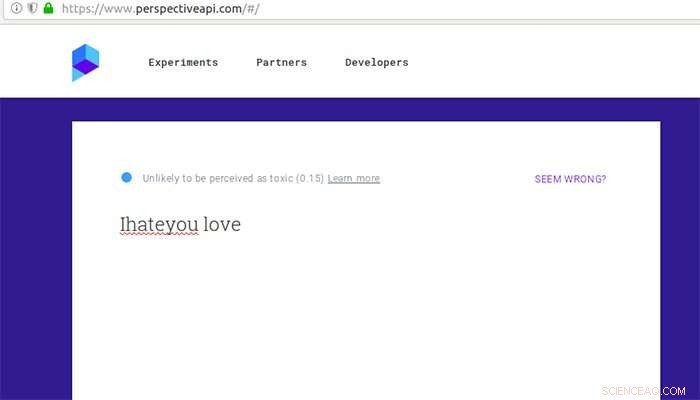
Hur Google Perspective betygsätter en kommentar som annars anses vara giftig efter några infogade stavfel och lite kärlek. Upphovsman:Aalto University
Hatlig text och kommentarer är ett ständigt ökande problem i onlinemiljöer, men att ta itu med den skenande frågan är beroende av att kunna identifiera giftigt innehåll. En ny studie från Aalto University Secure Systems forskargrupp har upptäckt svagheter i många detektorer för maskininlärning som för närvarande används för att känna igen och hålla hatprat i avstånd.
Många populära sociala medier och onlineplattformar använder hatdetaljer som ett team av forskare under ledning av professor N. Asokan nu har visat sig vara spröda och lätta att lura. Dålig grammatik och besvärlig stavning - avsiktligt eller inte - kan göra det svårare för giftiga sociala medier att kommentera sociala medier.
Teamet testade sju state-of-the-art hatdetaljdetektorer. Alla misslyckades.
Moderna naturliga språkbehandlingstekniker (NLP) kan klassificera text baserat på enskilda tecken, ord eller meningar. När de står inför textdata som skiljer sig från den som används i deras utbildning, de börjar famla.
"Vi satte in stavfel, ändrat ordgränser eller lagt till neutrala ord i det ursprungliga hatytret. Att ta bort mellanslag mellan ord var den mest kraftfulla attacken, och en kombination av dessa metoder var effektiv även mot Googles system för rankning av kommentarer, "säger Tommi Gröndahl, doktorand vid Aalto University.
Google Perspective rankar "toxicitet" av kommentarer med hjälp av textanalysmetoder. År 2017, forskare från University of Washington visade att Google Perspektiv kan luras genom att införa enkla stavfel. Gröndahl och hans kollegor har nu funnit att Perspektiv sedan har blivit motståndskraftigt mot enkla stavfel men ändå kan luras av andra modifieringar som att ta bort mellanslag eller lägga till oskyldiga ord som "kärlek".
En mening som "Jag hatar dig" gled genom silen och blev icke-hatisk när den ändrades till "Jag älskar dig".
Forskarna noterar att samma yttrande i olika sammanhang kan betraktas antingen som hatiskt eller bara stötande. Hatprat är subjektivt och kontextspecifikt, vilket gör textanalystekniker otillräckliga som fristående lösningar.
Forskarna rekommenderar att mer uppmärksamhet ägnas åt kvaliteten på datauppsättningar som används för att träna maskininlärningsmodeller - snarare än att förfina modelldesignen. Resultaten indikerar att teckenbaserad detektion kan vara ett hållbart sätt att förbättra nuvarande applikationer.
Studien genomfördes i samarbete med forskare från University of Padua i Italien. Resultaten kommer att presenteras på ACM AISec -workshopen i oktober.
Studien är en del av ett pågående projekt som kallas "Deception Detection via Text Analysis in the Secure Systems" vid Aalto University.