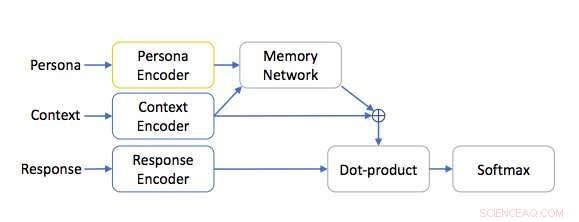
Persona-baserad nätverksarkitektur. Kredit:Mazaré et al.
Forskare på Facebook har nyligen sammanställt en datauppsättning med 5 miljoner personas och 700 miljoner persona-baserade dialoger. Denna databas kan användas för att träna dialogsystem från slut till ände, vilket resulterar i mer engagerande och rika dialoger mellan datoragenter och människor.
Dialogsystem, eller konversationsagenter (CA), är datorsystem utformade för att kommunicera med människor via text, Tal, grafik, eller andra metoder, på ett sammanhängande sätt. Än så länge, dialogsystem baserade på neurala arkitekturer, såsom LSTM eller minnesnätverk, har visat sig vara särskilt lovande när det gäller att uppnå flytande kommunikation, särskilt när de tränas direkt på dialogloggar.
"En av deras främsta fördelar är att de kan lita på stora datakällor från befintliga dialoger för att lära sig att täcka olika domäner utan att kräva någon expertkunskap, " skrev forskarna i sin tidning, som förpublicerades på arXiv. "Dock, baksidan är att de också uppvisar begränsat engagemang, speciellt i chit-chat-inställningar:De saknar konsekvens och utnyttjar inte proaktiva engagemangsstrategier som (även delvis) skriptade chatbots gör."
I en nyligen genomförd studie, ett annat team av forskare vid Montreal Institute for Learning Algorithms (MILA) och Facebook AI skapade en datauppsättning som heter PERSONA-CHAT, som inkluderar dialoger mellan agenter med textprofiler, eller personas, fäst vid dem. De fann att träning av ett dialogsystem om en viss person förbättrade deras engagemang i interaktioner.
"Dock, PERSONA-CHAT-datauppsättningen skapades med hjälp av en artificiell datainsamlingsmekanism baserad på Mechanical Turk, " förklarade forskarna i sin uppsats. "Som ett resultat, varken dialoger eller personas kan vara helt representativa för verkliga interaktioner mellan användare och bot och datauppsättningens täckning förblir begränsad, som innehåller lite mer än 1k olika personas."
För att ta itu med begränsningarna i den tidigare kompilerade datamängden, Facebook-forskarna skapade en ny, storskalig personbaserad dialogdatauppsättning, består av konversationer extraherade från onlineplattformen Reddit. Deras studie tar sina föregångares arbete ett steg längre, genom att använda mer representativa interaktioner.
"I det här pappret, vi bygger en mycket storskalig personbaserad dialogdatauppsättning med hjälp av konversationer som tidigare extraherats från Reddit, " skrev forskarna. "Med enkel heuristik, vi skapar en korpus på över 5 miljoner personas som spänner över mer än 700 miljoner konversationer."
För att utvärdera dess effektivitet, forskarna tränade personbaserade end-to-end dialogsystem på deras nyutvecklade dataset. System som tränats på deras datauppsättning kunde genomföra mer engagerande konversationer, överträffade andra samtalsagenter som inte hade tillgång till personas under sin utbildning.
Intressant, deras datauppsättning ledde till toppmoderna resultat även när dialogsystem bara var förutbildade på det. I framtiden, dessa fynd kan leda till utvecklingen av mer engagerande chatbots, som också kan anpassas och tränas för att förvärva en viss persona.
"Vi visar att träningsmodeller för att anpassa svaren både med författarens persona och sammanhanget förbättrar prestandan för att förutsäga, ", skrev forskarna. "Eftersom förträning leder till avsevärd förbättring av prestanda, framtida arbete skulle kunna finjustera denna modell för olika dialogsystem."
© 2018 Tech Xplore