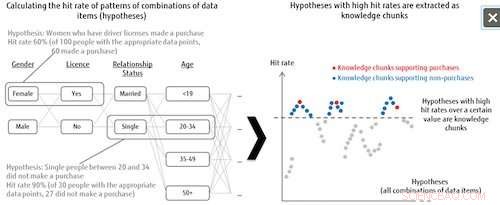
Figur 1:Hypoteslistning och utvinning av kunskapsbitar. Kredit:Fujitsu
Fujitsu Laboratories Ltd. tillkännagav idag utvecklingen av "Wide Learning, " en maskininlärningsteknik som kan göra exakta bedömningar även när operatörer inte kan få den mängd data som krävs för utbildning. AI används nu ofta för att utnyttja data inom en mängd olika områden, men noggrannheten hos AI kan påverkas i fall där mängden data som ska analyseras är liten eller obalanserad. Fujitsus Wide Learning-teknologi gör att bedömningar kan nås mer exakt än vad som tidigare varit möjligt, och lärande uppnås enhetligt, oavsett vilken hypotes som undersöks, även när informationen är obalanserad. Den uppnår detta genom att först extrahera hypoteser med hög grad av betydelse, efter att ha gjort en stor uppsättning hypoteser bildade av alla kombinationer av dataobjekt, och sedan genom att kontrollera graden av inverkan av varje respektive hypotes baserat på de överlappande förhållandena mellan hypoteserna. Dessutom, eftersom hypoteserna registreras som logiska uttryck, människor kan också förstå resonemanget bakom en dom. Fujitsus nya Wide Learning-teknologi tillåter användning av AI även inom områden som hälsovård och marknadsföring, där uppgifterna som behövs för att göra bedömningar är knappa, stödja verksamheten och främja automatisering av arbetsprocesser med hjälp av AI.
På senare år har AI-teknik har börjat användas inom en mängd olika områden, inklusive sjukvård, marknadsföring, och finans. Förväntningarna ökar på användningen av AI-beslutsfattande som stöd för operationer och automatiseringsuppgifter inom dessa områden. En utmaning som återstår att förverkliga potentialen i dessa tekniker, dock, är att uppgifterna kan vara obalanserade. Specifikt, beroende på bransch kan det vara svårt att få tillräckligt med data för att träna AI på de mål som den ska göra bedömningar på. Detta, i själva verket, gör att många av dessa tekniker inte kan ge resultat med tillräcklig noggrannhet för praktisk användning. Vidare, en viktig anledning till att AI-utbyggnaden saknar framsteg är att även när en AI ger tillräckligt exakt igenkännings- eller klassificeringsprestanda, experter och till och med utvecklarna själva kan ofta inte förklara varför AI gav ett visst svar, och om de inte kan uppfylla sitt ansvar att förklara resultaten för industrins frontlinjer kan AI inte användas.
AI-teknologier baserade på djupinlärning gör konventionellt mycket exakta bedömningar genom att tränas på stora datamängder, inklusive omfattande måldata att bedöma. I verkliga scenarier, dock, det finns många fall där uppgifterna är otillräckliga, med extremt lite måldata. I dessa fall, när man ställs inför okända data, det blir svårt för AI-teknik att leverera mycket exakta bedömningar. Dessutom, maskininlärningsmodellen för befintlig AI baserad på djupinlärning är en svart låda-modell som inte kan förklara orsakerna bakom de bedömningar som AI gör, skapar problem med transparensen. Som sådan, framåt kommer det att bli nödvändigt att utveckla ny AI-teknik som realiserar mycket exakta bedömningar från obalanserad data, och som också är transparent för att lösa olika frågor i samhället.
Med tanke på dessa utmaningar, Fujitsu Laboratories har nu utvecklat Wide Learning, en maskininlärningsteknik som kan göra mycket exakta bedömningar även i fall där data är obalanserad. Funktionerna i Wide Learning-tekniken inkluderar följande två punkter.
1. Skapar kombinationer av dataobjekt för att extrahera stora volymer av hypoteser
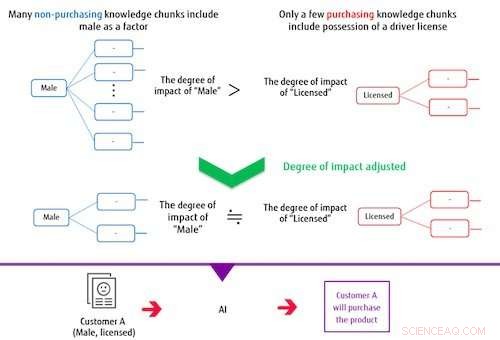
Figur 2:När du gör en klassificeringsmodell, kunskapsbitarna påverkar justering. Kredit:Fujitsu
Denna teknik behandlar alla kombinationsmönster av dataobjekt som hypoteser, och bestämmer sedan graden av betydelse för varje hypotes baserat på träfffrekvensen för etikettkategorin. Till exempel, när man analyserar trender i vem som köper vissa produkter, systemet kombinerar alla möjliga mönster från dataposterna för de som gjorde eller inte gjorde inköp (kategorietiketten), som ensamstående kvinnor mellan 20-34 som har körkort, och analyserar sedan hur många träffar det får i uppgifterna för de som faktiskt gjort köp när dessa kombinationsmönster tas som hypoteser. De hypoteser som uppnår en träfffrekvens över en viss nivå definieras som viktiga hypoteser, kallas "kunskapsbitar". Detta innebär att även när måldata är otillräckliga, systemet kan extrahera alla hypoteser som är värda att undersöka, vilket också kan bidra till upptäckten av tidigare oövervägda förklaringar.
2. Justerar graden av påverkan av kunskapsbitar för att bygga en korrekt klassificeringsmodell
Systemet bygger en klassificeringsmodell baserad på flera extraherade kunskapsbitar och på måletiketten. I denna process, om objekten som utgör en kunskapsbit ofta överlappar de artiklar som utgör andra kunskapsbitar, systemet kontrollerar deras grad av påverkan för att minska vikten av deras inflytande på klassificeringsmodellen. På det här sättet, systemet kan träna en modell som kan klassificera korrekt även när måletiketten eller data som är markerade som korrekta är obalanserade. Till exempel, i ett fall där män som inte gjorde ett köp utgör den stora majoriteten av en datauppsättning för varuköp, om AI:n tränas utan att kontrollera graden av påverkan, sedan kunskapsbiten som inkluderar om en person har en licens eller inte, oberoende av kön, kommer inte att ha mycket inflytande på klassificeringen. Med denna nyutvecklade metod, graden av inverkan av kunskapsbitar, inklusive manlig som en faktor, är begränsad på grund av överlappningen av denna artikel, medan effekten av det mindre antalet kunskapsbitar som inkluderar om en person har en licens blir relativt större i utbildningen, bygga en modell som korrekt kan kategorisera både män och innehav av licens.
Fujitsu Laboratories genomförde ett försök med denna teknik, tillämpa den på data inom områden som digital marknadsföring och hälsovård. I ett test med benchmarkdata inom marknadsförings- och hälsovårdsområdena från UC Irvine Machine Learning Repository, denna teknik förbättrade noggrannheten med cirka 10-20 % jämfört med djupinlärning. Det minskade framgångsrikt sannolikheten att systemet skulle förbise kunder som sannolikt prenumererar på en tjänst eller patienter med ett tillstånd med cirka 20-50 %. I marknadsföringsdata, av de cirka 5, 000 kunddatainmatningar som användes i testet, endast cirka 230 var för köpande kunder, skapar en obalanserad uppsättning. Denna teknik minskade antalet potentiella kunder som uteslutits från säljkampanjer från 120, resultatet av djupinlärningsanalys, till 74. Dessutom eftersom kunskapsbitarna som ligger till grund för denna teknik har ett logiskt uttrycksformat, förmågan att förklara resonemanget bakom en dom är också användbar för att implementera denna teknik i samhället. Även när det fastställs att korrigeringar av en modell är nödvändiga, baserat på resultat från nya data, det är möjligt att göra mer lämpliga ändringar, eftersom användarna kan förstå orsakerna till resultaten.
Fujitsu Laboratories kommer att fortsätta att tillämpa denna teknik på uppgifter som kräver resonemanget bakom AI-bedömningar, till exempel vid finansiella transaktioner och medicinska diagnoser, och till uppgifter som hanterar lågfrekventa fenomen, såsom bedrägerier och utrustningshaveri, med målet att kommersialisera den som en ny maskininlärningsteknik som stödjer Fujitsu Limiteds Fujitsu Human Centric AI Zinrai under räkenskapsåret 2019. Fujitsu Laboratories kommer också att effektivt använda denna tekniks karakteristiska förmåga för förklaring, fortsatt forskning och utveckling inom ämnen som förbättrat stöd för att fatta bedömningar och beslut i uppgifter som det tillämpas på, och in i den övergripande systemdesignen, inklusive samarbete med människor.