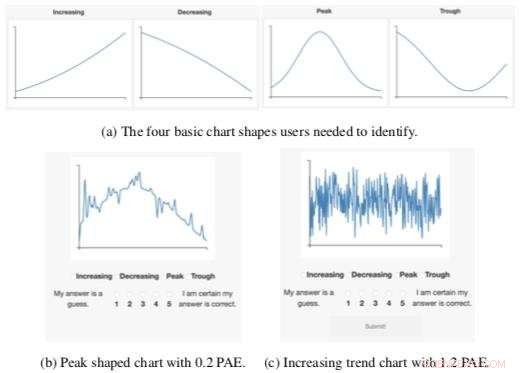
Bild som visar ett exempel på en av användarstudierna, där användare var tvungna att klassificera diagram baserat på deras form. Diagrammet till höger visar ett exempel på ett komplext diagram som skulle få en hög komplexitetspoäng (c). Intuitivt, det är svårare att läsa än diagrammet till vänster. För att förbättra läsbarheten, ett visualiseringsprogram skulle kunna förbättra viktiga aspekter av data för att göra det lättare att läsa. Kredit:Gabriel Ryan, Wu Lab/Columbia Engineering
Läkare som läser EEG på akutmottagningar, första responders tittar på flera skärmar som visar livedataflöden från sensorer i en katastrofzon, Mäklare som köper och säljer finansiella instrument behöver alla fatta välgrundade beslut mycket snabbt. Visualiseringskomplexitet kan komplicera beslutsfattande när man tittar på data på ett diagram. När timingen är kritisk, det är viktigt att ett diagram är lätt att läsa och tolka.
För att hjälpa beslutsfattare i scenarier som dessa, datavetare vid Columbia Engineering och Tufts University har utvecklat en ny metod — "Pixel Approximate Entropy" — som mäter komplexiteten i en datavisualisering och kan användas för att utveckla visualiseringar som är lättare att läsa. Eugene Wu, biträdande professor i datavetenskap, och Gabriel Ryan, som då var masterstudent och nu Ph.D. student vid Columbia, kommer att presentera sitt papper på IEEE VIS 2018-konferensen på torsdag, 25 oktober, i Berlin, Tyskland.
"Detta är ett helt nytt sätt att arbeta med linjediagram med många olika potentiella tillämpningar, säger Ryan, första författare på tidningen. "Vår metod ger visualiseringssystem ett sätt att mäta hur svåra linjediagram är att läsa, så nu kan vi designa dessa system för att automatiskt förenkla eller sammanfatta diagram som skulle vara svåra att läsa på egen hand."
Förutom att visuellt inspektera en visualisering, det har funnits få sätt att automatiskt kvantifiera komplexiteten i en datavisualisering. För att lösa det här problemet, Wus grupp skapade Pixel Approximate Entropy för att ge en "visuell komplexitetspoäng" som automatiskt kan identifiera svåra diagram. De modifierade ett lågdimensionellt entropimått för att fungera på linjediagram, och genomförde sedan en serie användarstudier som visade att måttet kunde förutsäga hur väl användarna uppfattade diagram.
"I snabba inställningar, det är viktigt att veta om visualiseringen kommer att bli så komplex att signalerna kan skymmas, säger Wu, som också är medordförande för Data, Media, &Samhällscentrum i Data Science Institute. "Förmågan att kvantifiera komplexitet är det första steget mot att automatiskt göra något åt detta."
Teamet förväntar sig deras system, som är öppen källkod, kommer att vara särskilt användbar för datavetare och ingenjörer som utvecklar AI-drivna datavetenskapssystem. Genom att tillhandahålla en metod som gör det möjligt för systemet att bättre förstå de visualiseringar det visar, Pixel Approximate Entropy kommer att hjälpa till att driva utvecklingen av mer intelligenta datavetenskapssystem.
"Till exempel, i industriell styrning kan en operatör behöva observera och reagera på trender i avläsningar från en mängd olika systemmonitorer över tiden, t.ex. vid en kemikalie- eller kraftverk, " Ryan tillägger. "Ett system som är medvetet om sjökorts komplexitet skulle kunna anpassa avläsningar för att säkerställa att operatören kan identifiera viktiga trender och minska tröttheten från att försöka tolka potentiellt brusiga signaler.
Wus grupp planerar att utöka datavisualiseringen till att använda dessa modeller för att automatiskt varna användare och designers när visualiseringar kan vara för komplexa och föreslå utjämningstekniker, och att utveckla andra kvantitativa perceptuella modeller som kan användas för design av databehandlings- och visualiseringssystem.