Uppmaning visas för läkare för kommentarer. Kredit:IBM
Den senaste tiden har sett betydande framsteg i förståelse av naturligt språk av AI, såsom maskinöversättning och frågesvar. En viktig orsak bakom denna utveckling är skapandet av datauppsättningar, som använder maskininlärningsmodeller för att lära sig och utföra en specifik uppgift. Konstruktion av sådana datamängder i den öppna domänen består ofta av text som härrör från nyhetsartiklar. Detta följs vanligtvis av insamling av mänskliga kommentarer från crowd-sourcing-plattformar som Crowdflower, eller Amazon Mechanical Turk.
Dock, språk som används inom specialiserade domäner som medicin är helt annorlunda. Ordförrådet som används av en läkare när han skriver en klinisk anteckning är helt olik orden i en nyhetsartikel. Således, Språkuppgifter inom dessa kunskapsintensiva domäner kan inte samlas på crowdsourcing eftersom sådana kommentarer kräver domänexpertis. Dock, Det är också mycket dyrt att samla in kommentarer från domänexperter. Dessutom, Klinisk data är integritetskänslig och kan därför inte delas enkelt. Dessa hinder har hämmat bidraget från språkdatauppsättningar inom den medicinska domänen. På grund av dessa utmaningar, validering av högpresterande algoritmer från den öppna domänen på kliniska data förblir outforskad.
För att komma till rätta med dessa luckor, vi arbetade med Massachusetts Institute of Technology för att bygga MedNLI, en datauppsättning kommenterad av läkare, utföra en naturlig språkinferens (NLI) uppgift och grundad i patienternas medicinska historia. Viktigast, vi gör det allmänt tillgängligt för forskare att främja naturlig språkbehandling inom medicin.
Vi arbetade med MIT Critical Data Research Labs för att konstruera en datauppsättning för naturliga språkinferenser inom medicin. Vi använde kliniska anteckningar från deras "Medical Information Mart for Intensive Care" (MIMIC) databas, som utan tvekan är den största allmänt tillgängliga databasen med patientjournaler. Klinikerna i vårt team föreslog att en patients tidigare medicinska historia innehåller viktig information från vilken användbara slutsatser kan dras. Därför, vi extraherade den tidigare medicinska historien från kliniska anteckningar i MIMIC och presenterade en mening från denna historia som en premiss för en kliniker. De ombads sedan att använda sin medicinska expertis och generera tre meningar:en mening som definitivt var sann om patienten, med tanke på premissen; en mening som definitivt var falsk, och till sist en mening som möjligen kan vara sann.
Under några månader, vi tog slumpmässigt 4, 683 sådana lokaler och arbetade med fyra kliniker för att konstruera MedNLI, en datauppsättning på 14, 049 premisshypotespar. I den öppna domänen, andra exempel på liknande uppbyggda datamängder inkluderar Stanford Natural Language Inference dataset, som kurerades med hjälp av 2, 500 arbetare på Amazon Mechanical Turk och består av 0,5 miljoner premiss-hypotespar där premisssatser drogs från bildtexter på Flickr-foton. MultiNLI är en annan och består av premisstext från specifika genrer som fiktion, bloggar, telefonsamtal, etc.
Dr. Leo Anthony Celi (Principal Scientist for MIMIC) och Dr. Alistair Johnson (Research Scientist) från MIT Critical Data arbetade med oss för att göra MedNLI allmänt tillgängligt. De skapade MIMIC Derived Data repository, Till vilken MedNLI agerade som det första bidraget till datauppsättningen för bearbetning av naturligt språk. Alla forskare med tillgång till MIMIC kan också ladda ner MedNLI från detta förråd.
Även om de har en blygsam storlek jämfört med datauppsättningarna för öppna domäner, MedNLI är tillräckligt stor för att informera forskare när de utvecklar nya maskininlärningsmodeller för språkinferens inom medicin. Viktigast, det ger intressanta utmaningar som kräver innovativa idéer. Betrakta några exempel från MedNLI:
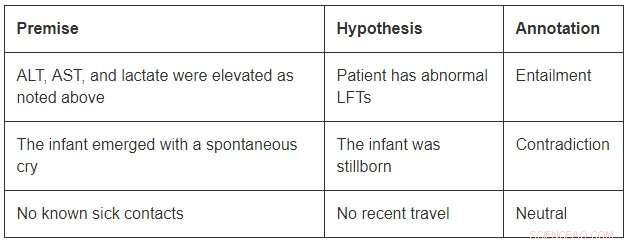
För att avsluta innebörden i det första exemplet, man borde kunna utöka förkortningarna ALT, AST, och LFTs; förstå att de är relaterade; och dra vidare slutsatsen att en förhöjd mätning är onormal. Det andra exemplet visar en subtil slutsats av att dra slutsatsen att ett spädbarns uppkomst är en beskrivning av dess födelse. Till sist, det sista exemplet visar hur vanlig världskunskap används för att härleda slutsatser.
Toppmoderna algoritmer för djupinlärning kan prestera mycket på språkuppgifter eftersom de har potential att bli mycket bra på att lära sig en korrekt kartläggning från indata till utdata. Således, Att träna på en stor datamängd som kommenteras med hjälp av anteckningar från publiken är ofta ett framgångsrecept. Dock, de saknar fortfarande generaliseringsförmåga under förhållanden som skiljer sig från de man stöter på under träning. Detta är ännu mer utmanande inom specialiserade och kunskapsintensiva områden som medicin, där träningsdata är begränsad och språket är mycket mer nyanserat.
Till sist, även om stora framsteg har gjorts för att lära sig en språkuppgift från början, det finns fortfarande ett behov av ytterligare tekniker som kan införliva expertkurerade kunskapsbaser i dessa modeller. Till exempel, SNOMED-CT är en expertkurerad medicinsk terminologi med över 300 000 koncept och relationer mellan termerna i dess datauppsättning. Inom MedNLI, vi gjorde enkla modifieringar av befintliga djupa neurala nätverksarkitekturer för att ingjuta kunskap från kunskapsbaser som SNOMED-CT. Dock, en stor mängd kunskap är fortfarande outnyttjad.
Vi hoppas att MedNLI öppnar upp nya forskningsriktningar inom det naturliga språkbearbetningssamhället.
Den här historien återpubliceras med tillstånd av IBM Research. Läs originalberättelsen här.