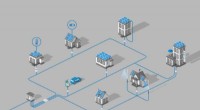
Ett illustrativt exempel på jämförande sammanfattning. Rutor är nyhetsartiklar, rader betecknar olika nyhetskanaler, och x-axeln anger tid. De skuggade artiklarna är valda att representera AI-relaterade nyheter under februari och mars 2018, respektive. De syftar till att sammanfatta ämnen i varje månad och även lyfta fram skillnader mellan de två månaderna. Kredit:Bista et al.
Forskare vid Australian National University (ANU) har nyligen genomfört en studie som utforskar extraktiv sammanfattning i jämförande miljöer. Termen "extraktiv sammanfattning" definierar uppgiften att välja ut några mycket representativa artiklar från en stor samling dokument.
I deras tidning, förpublicerad på arXiv och kommer att presenteras vid den 33:e AAAI-konferensen om artificiell intelligens, forskarna övervägde jämförande sammanfattningar, vilket innebär urval av dokument från olika dokumentsamlingar. Dessa utvalda dokument bör vara representativa för varje grupp, samtidigt som man lyfter fram skillnader mellan grupperna.
Projektet följer ett pågående tema vid ANU:s Computational Media Lab, som fokuserar på automatiserad förståelse av stora mängder text- och bildströmmar på den sociala webben. Ett övergripande mål med studien är att identifiera tekniker som kan hjälpa människor att hantera informationsöverbelastning.
"Det finns för mycket nytt innehåll för någon att läsa:nyheter, sociala medier flöden, eller till och med strömmen av arXiv-forskningsartiklar, "Lexing Xie, en av forskarna som genomförde studien, berättade för TechXplore. "Kan vi be datorer att hjälpa oss välja vilken vi ska läsa, och fortfarande få viktig information?"
Xie och hennes kollegor har undersökt sätt att sammanfatta hundratusentals nyhetsartiklar, inlägg och diskussioner tillgängliga online. Deras syfte är att ge användarna några (t.ex. 3-4) objekt som bäst svarar på frågan "vad är nytt?" över en viss tidsram (t.ex. idag, Denna vecka, etc.) eller om ett visst ämne (t.ex. klimatförändringar, val, etc.).
"Textsammanfattning har varit ett aktivt forskningsfält i nästan 20 år, men huvudfokus har varit att sammanfatta en samling antingen extraktivt (dvs. välj befintliga objekt för att sammanfatta en sammanfattning), eller abstrakt (d.v.s. komponera nya meningar som sammanfattning, istället för att använda befintliga), " Xie förklarade. "Detta arbete fokuserar på extraktiv jämförelse av dokumentgrupper, d.v.s. att välja ett fåtal objekt från en grupp som är mest skild från andra grupper. Som vi förstår det, vårt arbete är det första som utför och validerar jämförande sammanfattningar i stor skala."
I deras studie, forskarna närmade sig jämförande dokumentsammanfattning som en klassificeringsuppgift. Klassificering är en vanlig maskininlärningsuppgift, där en algoritm gör välgrundade gissningar om vilken kategori eller vilka grupper specifika dataobjekt hör hemma i.
"När det gäller jämförande sammanfattningar, om vi har valt bra sammanfattningsartiklar borde det vara svårt, om inte omöjligt, att utforma en klassificerare som kan skilja mellan de valda sammanfattningsartiklarna och de grupper som de tillhör; medan det ska vara enkelt att utforma en klassificerare som kan skilja mellan de valda sammanfattningsartiklarna och andra grupper, "Alexander Mathews, en annan forskare involverad i studien, berättade för TechXplore.
Forskarnas klassificeringsperspektiv innebär en alternativ men kompletterande syn på jämförande sammanfattning som tre konkurrerande mål. Först, utvalda sammanfattningsartiklar ska vara representativa för de grupper som de tillhör, täcker alla viktiga aspekter av dokumentsamlingen.
Andra, varje vald sammanfattningsartikel bör vara relativt annorlunda än de andra, för att undvika onödiga upprepningar. Till sist, utvalda sammanfattningsartiklar bör endast vara representativa för den grupp de tillhör, eftersom detta är en nyckelfaktor för effektiv jämförande sammanfattning.
"Vår specifika formulering av de tre målen bygger på ett flexibelt matematiskt mått som kallas Maximum Mean Discrepancy (MMD), " förklarade Mathews. "Detta mått, Tillsammans med tillämpningen av ett matematiskt verktyg som kallas "kärntricket" kan vi gjuta våra tre mål till en kompakt matematisk form som vi kan optimera effektivt även på stora datamängder. Dessutom, denna form tillåter både diskreta och gradientbaserade optimeringstekniker, så att valet av artiklar kan finjusteras för att uppfylla våra mål."
Det klassificeringsperspektiv som Mathews och hans kollegor tog tillät dem att utvärdera sin metod som en klassificeringsuppgift, både automatiskt och via crowdsourcing. Deras tillvägagångssätt överträffade diskreta och baslinjemetoder i 15 av 24 automatiska utvärderingsinställningar. I crowdsourcing-utvärderingar, Sammanfattningar som valts ut med deras enkla gradientbaserade optimeringsstrategi framkallade 7 % mer exakt klassificering från mänskliga arbetare än diskreta optimeringsmetoder.
"Vi är glada att se att med endast 4 sammanfattande artiklar per vecka är noggrannheten i den automatiska klassificeringen (av varje nyhetsartikel i månaden/veckan som den kom ifrån) i paritet med en som "läser" alla artiklar, "Minjeong Shin, en av forskarna som genomförde studien, berättade för TechXplore. "Detta visar att viktig ny information finns i de få "prototyp"-artiklarna."
Forskarna utvärderade sin metod mot andra tillvägagångssätt på en nyligen kurerad samling av kontroversiella nyhetsämnen som sträcker sig över 13 månader. När den tillämpas på den jämförande sammanfattningen av pågående innehållsströmmar, deras system besvarade framgångsrikt frågor som "vad är nytt i ämnet klimatförändringar den här månaden?", belyser skillnader mellan två distinkta tidsperioder.
"Vår metodik gäller även andra samlingsjämförelser än nyheter över tid, " sa Shin. "Till exempel, man kan fråga sig:vad är skillnaden mellan BBC och CNNs bevakning av G20-toppmötet, eller hur skiljer sig bevakningen av klimatförändringar mellan brittiska och australiska medier?"
I framtiden, detta nya tillvägagångssätt för jämförande sammanfattningar skulle kunna hjälpa användare att navigera i de stora mängderna information som finns tillgänglig online. tillhandahålla jämförelser av artiklar publicerade av olika källor eller författare, samt av inlägg om relaterade ämnen eller som uttrycker distinkta åsikter. Forskarna arbetar nu med att utöka sin forskning genom att ta dessa jämförelser till nästa nivå.
"Vi undersöker sätt att sammanfatta inte bara text, men även bilder och text tillsammans, "Umanga Bista, en av forskarna som genomförde studien, berättade för TechXplore. "Vi skulle också vilja ta hänsyn till kända relationer mellan enheter som nämns i texten (t.ex. Delhi är Indiens huvudstad), snarare än att behandla varje ord som en självständig enhet. I sista hand, vi skulle vilja ha ett system som rekommenderar vad som är nytt, vad är skillnaden, och vad som är värt att läsa."
© 2018 Science X Network