
En medelbaserad modell av medfödd immunsvar simulerar mekaniskt sepsis i 2-D. Kredit:Lawrence Livermore National Laboratory
En djupinlärningsmetod som ursprungligen utformades för att lära datorer hur man spelar videospel bättre än människor kan hjälpa till att utveckla personlig medicinsk behandling för sepsis, en sjukdom som orsakar cirka 300, 000 dödsfall per år och för vilka det inte finns något känt botemedel.
Lawrence Livermore National Laboratory (LLNL), i samarbete med forskare vid University of Vermont, undersöker hur djup förstärkningsinlärning kan upptäcka terapeutiska läkemedelsstrategier för sepsis genom att använda en simulering av en patients medfödda immunsystem som en plattform för virtuella experiment. Djup förstärkningsinlärning är en toppmodern metod för maskininlärning som ursprungligen utvecklades av Google DeepMind för att lära ett neuralt nätverk hur man spelar videospel, ges endast pixlar som indata och spelets poäng som en inlärningssignal. Algoritmerna överstiger ofta mänsklig prestation, trots att man inte fått någon kunskap om spelets mekanik.
LLNL:s djupinlärningsmetod behandlar immunsystemsimuleringen som utvecklats av deras medarbetare som ett tv -spel. Med hjälp av utdata från simuleringen, ett "poäng" baserat på patientens hälsa och en optimeringsalgoritm, det neurala nätverket lär sig hur man manipulerar 12 olika cytokinmediatorer – immunsystemregulatorer – för att driva tillbaka immunsvaret på infektion till normala nivåer. Forskningen visas i en artikel publicerad av International Conference on Machine Learning.
"Det är ett komplext system, " sa LLNL-forskaren Dan Faissol, huvudutredare för projektet. "Tidigare undersökningar har hittills baserats på att manipulera en enda mediator/cytokin, administreras vanligtvis med antingen en engångsdos eller under en mycket kort behandling. Vi tror att vårt tillvägagångssätt har stor potential eftersom det utforskar mycket mer komplexa, out-of-the-box terapeutiska strategier som behandlar varje patient på olika sätt baserat på patientens mätningar över tid."
Den behandlingsstrategi som forskarna föreslår är adaptiv och personlig, förbättra sig själv på en återkopplingsslinga genom att kontinuerligt observera cytokinnivåer och förskriva läkemedel specifika för den enskilda patienten. Varje körning av simuleringen representerar en annan patienttyp och olika initiala infektionsförhållanden.
"Utmaningen var att hålla saker kliniskt relevanta, " förklarade LLNL-forskaren Brenden Petersen, den tekniska ledaren för projektet. "Vi var tvungna att se till att alla aspekter av det simulerade problemet var relevanta i den verkliga världen - att datorn inte använde någon information som egentligen inte skulle vara tillgänglig på ett sjukhus. Så, vi försåg bara det neurala nätverket med information som faktiskt kan mätas kliniskt, som cytokinnivåer och cellantal från en blodtagning."
Genom att använda den agentbaserade modellen med djup förstärkningsinlärning, forskare identifierade en behandlingspolicy som uppnår en överlevnadsgrad på 100 procent för de patienter som den utbildades på, och en dödlighet på mindre än 1 procent på 500 slumpmässigt utvalda patienter.
"Simuleringen är mekanistisk till sin natur, vilket innebär att vi praktiskt taget kan experimentera med läkemedel och läkemedelskombinationer som inte har testats tidigare för att se om de kan vara lovande, "Sa Faissol." Antalet möjliga behandlingsstrategier är enormt, särskilt när man överväger strategier för flera läkemedel som varierar över tiden. Utan att använda simulering, det finns inget sätt att utvärdera dem alla. Det svåra är att upptäcka en strategi som fungerar för alla patienttyper. Allas infektion är olika, och allas kropp är olika."
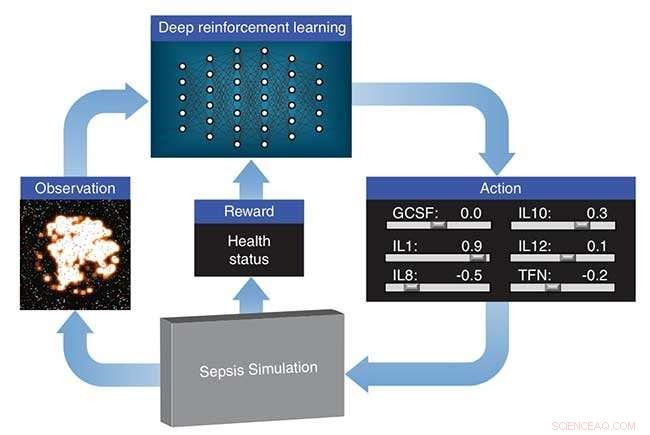
LLNL:s djupinlärningsmetod behandlar immunsystemets simulering som utvecklats av deras medarbetare som ett videospel. Med hjälp av utdata från simuleringen, ett "poäng" baserat på patientens hälsa och en optimeringsalgoritm, det neurala nätverket lär sig hur man manipulerar 12 olika cytokinmediatorer – immunsystemregulatorer – för att driva tillbaka immunsvaret på infektion till normala nivåer. Kredit:Lawrence Livermore National Laboratory
Teamets forskning har visat att detta adaptiva tillvägagångssätt kan leda till nya insikter, och forskarna hoppas kunna övertyga andra att anta metoden för sepsis och andra sjukdomar.
"Vår storslagna, långtidsseende är ett "closed-loop" sängsystem där mätningar från en patient matas in i ett beslutsstödjande verktyg, som sedan administrerar rätt läkemedel i rätt doser vid rätt tidpunkter, "Sådana behandlingsstrategier måste först granskas och finjusteras i våtlabb- och djurmodeller, sa Petersen. så småningom informera om riktiga behandlingar."
Petersen sa att det mesta av hårdvaran för att köra ett sådant slutet system redan existerar, som med enklare system som insulinpumpar som ständigt övervakar blodet och administrerar insulin vid rätt tidpunkt.
Labbets djupförstärkande inlärningsmetod har ännu inte testats i den verkliga världen, men baserat på framgången med simuleringen, National Institutes of Health tilldelade forskare från LLNL och University of Vermont ett femårigt anslag för att fortsätta arbetet, främst på sepsis men även på cancer.
"Det här är ett spännande projekt, sa Gary An, en intensivvårdsläkare vid University of Vermont och beräkningsforskare som utvecklade den ursprungliga versionen av sepsissimuleringen. "Detta är ett otroligt nytt projekt som sammanför tre banbrytande områden inom beräkningsforskning:högupplösta flerskaliga simuleringar av biologiska processer, utvidgning av djup förstärkningsinlärning till biomedicinsk forskning och användningen av högpresterande datorer för att få ihop allt."
LLNL:s chef för Bioengineering Shankar Sundaram beskrev tillvägagångssättet som "ett illustrativt exempel på labbet som bidrar till utvecklingen av en potentiell terapeutisk lösning på ett komplext hälsoproblem som är avgörande för vårt biosäkerhetsuppdrag, att tillämpa och utveckla vår toppmoderna kapacitet inom vetenskaplig maskininlärning och inrikta sig på förbättrade orsakssamband, mekanistisk förståelse."
LLNL-forskare har också inlett ett samarbete med Moffitt Cancer Center i Florida för att se om ett liknande tillvägagångssätt kan lära sig effektiva läkemedelsterapistrategier med hjälp av en simulering av cancer. Moffitt släppte en videospelversion av deras simulering som heter "Cancer Crusade" som körs på mobiltelefoner.
"En strategi är att crowdsource lärandet genom att analysera behandlingar inspelade från de bästa spelarna runt om i världen, ", sa Petersen. "Vi tillämpade vår djupinlärningsmetod och vill se hur våra datoriserade behandlingar står sig mot toppspelarna – en "man vs. machine"-uppgörelse."
The sepsis project also has led to a new effort at LLNL researching adaptive and autonomous cyberdefense strategies using simulation and deep reinforcement learning.














