Upphovsman:Prasad, Das &Bhowmick.
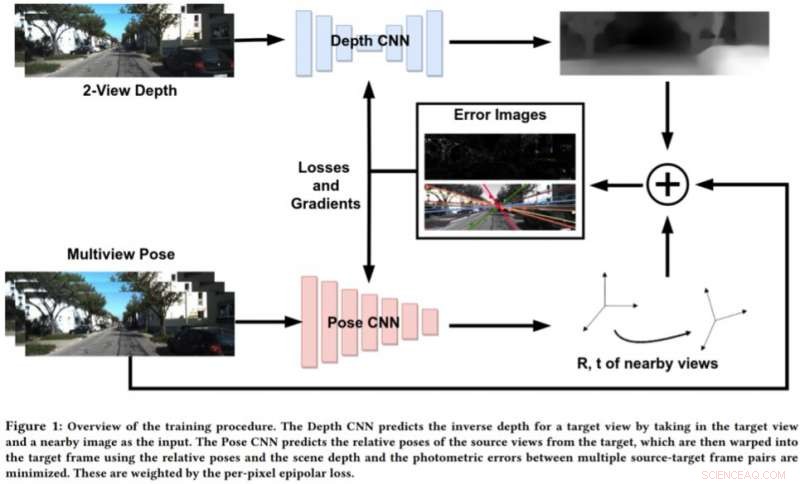
Forskare från gruppen Embedded Systems and Robotics vid TCS Research &Innovation har nyligen utvecklat ett djupnätverk med två vyer för att dra djup och ego-rörelse från på varandra följande monokulära sekvenser. Deras tillvägagångssätt, presenterad i ett papper som för publicerats på arXiv, innehåller också epipolära begränsningar, som förbättrar nätverkets geometriska förståelse.
"Vår huvudsakliga idé var att försöka förutspå pixelvis djup och kamerarörelse direkt från enstaka bildsekvenser, "Dr Brojeshwar Bhowmick, en av forskarna som genomförde studien, berättade TechXplore. "Traditionellt, struktur från rörelsebaserade rekonstruktionsalgoritmer ger glesa djuputgångar för framträdande intressanta platser i bilden, som spåras över flera bilder med hjälp av multi-view geometri. Med djupinlärning som blir allt populärare i datorvisionsuppgifter, vi tänkte utnyttja befintliga metoder för att hjälpa vår sak genom att närma oss problemet på ett mer grundläggande sätt med hjälp av en kombination av begrepp från epipolär geometri och djupinlärning. "
De flesta befintliga metoder för djupinlärning för att förutsäga monokulärt djup och egorörelse optimerar den fotometriska konsistensen i bildsekvenser genom att förvränga en vy till en annan. Genom att dra djup från en enda vy, dock, dessa metoder kan misslyckas med att fånga upp förhållandet mellan pixlar och därmed ge korrekta pixelkorrespondenser.
För att ta itu med begränsningarna i dessa tillvägagångssätt, Bhowmick och hans kollegor utvecklade ett nytt tillvägagångssätt som kombinerar geometrisk datorsyn och djupinlärande paradigm. Deras tillvägagångssätt använder två neurala nätverk, en för att förutsäga djupet för en enda referensvy och en för att förutsäga de relativa ställningarna för en uppsättning vyer med avseende på referensvyn.

Upphovsman:Prasad, Das &Bhowmick.
"Målbildscenen kan rekonstrueras från vilken som helst av de givna poserna genom att förvränga dem baserat på djupet och relativa poser, "Bhowmick förklaras." Med tanke på denna rekonstruerade bild och referensbilden, vi beräknar felet i pixelintensiteterna, som fungerar som vår största förlust. Vi lägger till nyheten att använda epipolär förlust per pixel, ett koncept från multi-view geometri, i den totala förlusten, vilket säkerställer bättre överensstämmelse och har den extra fördelen att rabattera rörliga föremål i scenen som annars kan försämra inlärningen. "
Istället för att förutsäga djup genom att analysera en enda bild, detta nya tillvägagångssätt fungerar genom att analysera ett par bilder från en video och lära sig interpixelrelationer för att förutsäga djup. Det liknar något traditionella SLAM/SfM -algoritmer, som kan observera pixelrörelser över tiden.
"De mest meningsfulla resultaten av vår studie är att användning av två vyer för att förutsäga djupet fungerar bättre än en enda bild, och att även svag tillämpning av pixelnivåkorrespondenser via epipolära begränsningar fungerar bra, "Sa Bhowmick." När sådana metoder mognar och förbättras i generaliserbarhet, vi kan tillämpa dem för uppfattning om drönare, där man vill extrahera maximal sensorisk information genom att konsumera så lite ström som möjligt, som kan uppnås med en enda kamera. "
I preliminära utvärderingar, forskarna fann att deras metod kunde förutsäga djup med högre noggrannhet än befintliga tillvägagångssätt, producera skarpare djupuppskattningar och förbättrade posestimat. Dock, för närvarande, deras tillvägagångssätt kan endast utföra slutsatser på pixelnivå. Framtida arbete skulle kunna hantera denna begränsning genom att integrera scenens semantik i modellen, vilket kan leda till bättre korrelationer mellan objekt i scenen och både djup- och ego-rörelsestimat.
"Vi undersöker vidare generaliserbarheten av denna metod och andra liknande metoder på olika scener, både inomhus och utomhus, "Sa Bhowmick." För närvarande, de flesta verk fungerar bra på utomhusdata, som kördata, men presterar mycket dåligt på inomhussekvenser med godtyckliga rörelser. "
© 2019 Science X Network