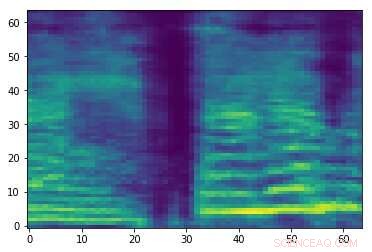
Spektrogram av en slumpmässig ljudsignal. Kredit:Esmailpour, Cardinal &Lemeiras Koerich.
Motstridiga ljudattacker är små störningar som inte kan uppfattas av människor och som avsiktligt läggs till ljudsignaler för att försämra prestandan hos modeller för maskininlärning (ML). Dessa attacker väcker allvarliga farhågor om säkerheten för ML-modeller, eftersom de kan få dem att göra misstag och i slutändan generera fel förutsägelser.
Forskare vid École de Technologie Supérieure, en del av University of Quebec i Kanada har nyligen utvecklat ett nytt tillvägagångssätt som kan hjälpa till att säkra ljudklassificeringsverktyg mot kontradiktoriska attacker. I deras tidning, förpublicerad på arXiv, de granskar några av de starkaste befintliga motståndarangreppen och deras inverkan på prestanda för vanliga ML -modeller, föreslå sedan ett tillvägagångssätt som kan motverka dessa attacker.
"Just nu, det finns många starka och snabba (vid körning) klassificerare när det gäller noggrannhet, nämligen djupinlärningsklassificerare (t.ex. konvolutionella neurala nätverk), som till och med kan överträffa mänsklig nivå av media (t.ex. tal, bild, video, animering, text, etc.) igenkänning och regression, "Mohammad Esmaeilpour, en av forskarna som genomförde studien, berättade för TechXplore. "Akilleshälen för dessa avancerade algoritmer är deras sårbarhet för indata som innehåller noggrant utformade störningar, känd som motstridiga attacker."
Motstridiga attacker fungerar genom att producera prover som liknar legitima träningsprover, men det leder faktiskt till att en eller flera ML-modeller genererar fel etiketter med höga konfidensnivåer. Inom ML-forskning, om det finns tillräckligt med data för att träna en klassificerare, den viktigaste utmaningen är inte längre att förbättra dess igenkänningsnoggrannhet, men att säkerställa dess motståndskraft mot fientliga attacker.
"Motstridiga attacker är aktiva hot för alla datadrivna algoritmer, även de som tränats på små datamängder, ", sade Esmaeilpour. "Detta väckte vårt intresse för att studera hotet om kontradiktoriska attacker för ljud- och taligenkänningsapplikationer, eftersom alla smartphones nu är utrustade med en virtuell talassistent som Siri, Google Assistant och Cortana."
I deras studie, Esmaeilpour och hans kollegor utförde experiment som involverade miljöljuddataset, snarare än taluppsättningar. Ändå, i framtiden skulle deras tillvägagångssätt också potentiellt kunna utvidgas till taligenkänning, som skulle hjälpa till att säkra röstassistenter mot motståndskraftiga attacker.
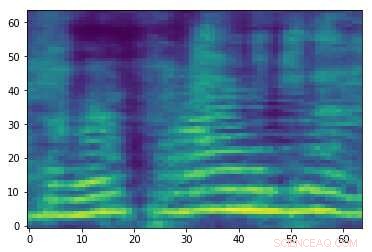
Tillverkat motstridigt spektrogram associerat med ljudsignalen i den första bilden. Även om de två bilderna är lika, de har olika etiketter, tyder på att en attack äger rum. Kredit:Esmailpour, Cardinal &Lemeiras Koerich.
"Vårt huvudmål i den här artikeln var att studera hotet från kontradiktoriska attacker för både konventionella och djupinlärningsljudklassificerare och idealiskt föreslå en mer tillförlitlig algoritm när det gäller motståndskraft mot några vanliga attacker som en baslinje mot verklig robust ljudklassificering, " Esmaeilpour förklarade. "Vi ville göra en rättvis balans för klassificerare i igenkänningsnoggrannhet, beräkningskomplexitet, och robusthet mot fientliga attacker."
Rent generellt, klassificerare som är mer robusta mot kontradiktoriska attacker uppnår lägre igenkänningsnoggrannhet, och vice versa. I deras studie, forskarna fokuserade på kontradiktorisk omskolning, en av de mest giltiga befintliga försvarsteknikerna som inte fördunklar gradientinformation. Trots dess fördelar, just denna försvarsstrategi är kostsam (eftersom starka attacker är dyra, kontradiktorisk omskolning med dessa attacker kommer att bli dyrare) och kan negativt påverka en klassificerares igenkänningsprestanda.
"Det ideala fallet för oss skulle vara att föreslå en gradientförvirringsfri och motstridig omskolningsfri ljudklassificerare som i sig lär sig "robusta funktioner", "Sa Esmaeilpour." Vårt klassificeringsscenario innehåller flera steg, främst spektrogram (2D-representation för ljudsignaler) förbättring, dimensionsreduktion med en algebraisk nedbrytningsteknik, och utjämning genom att använda en konvolutionell ljudlös autoencoder, där de två sista stegen (sammanlagda) har visat positiva effekter på att ta bort små okända potentiella motstridiga störningar."
Efter att ha granskat några av de starkaste motstridiga attackerna som finns och deras effekter på prestandan hos ML-modeller, forskarna extraherade funktioner från spektrogrammen som bearbetats av modellerna, organiserade dem i en kodbok och tränade en SVM-algoritm (support vector machine) på denna kodbok. I deras utbildningspipeline, de implementerade inte några proaktiva eller reaktiva metoder för att upptäcka attacker mot attacker eller försvarsalgoritmer.
"Vårt huvudmål var att "lära oss robusta funktionsvektorer" utan någon för- eller efterbehandlingsoverhead för att upptäcka potentiella kontradiktoriska prover, " Esmaeilpour förklarade. "Våra resultat visar att vår föreslagna klassificerare överträffar toppmoderna djupinlärning och konventionella algoritmer mot fem typer av starka motståndsattacker för vissa praktiska miljöljuddataset."
Esmaeilpour och hans kollegor bevisade statistiskt sårbarheten för både konventionella klassificerare (dvs. klassificerare som lär sig av funktionsutrymme) och algoritmer för djupinlärning (dvs. algoritmer som lär sig av rådata) mot motsatta attacker. Enligt forskarna, det finns för närvarande ingen tillförlitlig datadriven algoritm för ljudklassificering som också är robust mot kontradiktoriska attacker. Bland befintliga modeller, djupinlärningsbaserade metoder verkar vara minst säkra mot dessa attacker, även om de vanligtvis uppnår den högsta igenkänningsnoggrannheten.
"Klassificeringsscenariot vi föreslog i vårt dokument använder en SVM med polynomkärna som en slutklassificerare, " sade Esmaeilpour. "Men, att tillämpa en faltningsavlägsnande autoencoder ovanpå singulära värdenedbrytning följt av en oövervakad klustring av extraherade påskyndade robusta funktionsvektorer kan hjälpa till att lära sig fler strukturella komponenter och förmodligen robusta funktioner, vilket kan göra det möjligt för oss att uppnå en rimlig balans mellan igenkänningsnoggrannhet (jämförbar med toppmodern prestanda) och robusthet mot fem vanliga starka motstridiga attacker. "
Även om resultaten som samlats in av forskarna är mycket lovande, de kan variera beroende på vilken datauppsättning som används eller en klassificerares specifika tillämpning, därför är de ännu inte generaliserbara. I framtiden, deras studie skulle kunna informera om utvecklingen av andra klassificerare som är bättre rustade mot kontradiktoriska attacker, utan att ge betydande prestandaförluster (d.v.s. igenkänningsnoggrannhet).
"Att lära sig robusta funktioner är ett öppet problem och vi har fortfarande ingen klar uppfattning om hur vi ska hantera det på rätt sätt; det studeras av vårt forskargrupp och några resultat kommer att släppas snart, " sa Esmaeilpour. "Under tiden, vi jobbar på en ny, stark och snabb motsatt angreppsteknik som syftar till att använda denna attack för att motsatt träna inlärningsmodellen (vilket förbättrar dess robusthet) och också spara modellens erkännandeprestanda innan den tränas. "
© 2019 Science X Network