Forskarnas laboratorium, sett av den dynamiska synsensorn. Kredit:Perception and Robotics Group, University of Maryland.
Houston Astros José Altuve kliver upp till plattan på en 3-2-räkning, studerar kannan och situationen, får klartecken från tredje bas, spårar bollens släpp, gungar ... och får en singel i mitten. Bara ännu en resa till plattan för den trefaldiga amerikanska ligamästaren.
Kan en robot få en träff i samma situation? Inte troligt.
Altuve har finslipat naturliga reflexer, År av erfarenhet, kunskap om kannans tendenser, och förståelse för banorna på olika platser. Vad han ser, hör, och känns sömlöst kombinerat med hjärnan och muskelminnet för att ta tid på svingen som producerar träff. Roboten, å andra sidan, måste använda ett kopplingssystem för att långsamt koordinera data från sina sensorer med dess motoriska kapacitet. Och det kommer inte ihåg något. Strike tre!
Men det kan finnas hopp för roboten. Ett papper av University of Maryland -forskare som just publicerats i tidskriften Science Robotics introducerar ett nytt sätt att kombinera perception och motorkommandon med hjälp av den så kallade hyperdimensionella beräkningsteorin, som i grunden kan förändra och förbättra den grundläggande artificiella intelligensen (AI) för sensormotorisk representation - hur agenter som robotar översätter vad de känner till vad de gör.
"Learning Sensorimotor Control with Neuromorphic Sensors:Toward Hyperdimensional Active Perception" skrevs av datavetenskap Ph.D. studenterna Anton Mitrokhin och Peter Sutor, Jr.; Cornelia Fermüller, en associerad forskare med University of Maryland Institute for Advanced Computer Studies; och datavetenskapsprofessor Yiannis Aloimonos. Mitrokhin och Sutor råds av Aloimonos.
Integration är den viktigaste utmaningen för robotfältet. En robotsensorer och ställdon som rör den är separata system, sammanlänkade av en central inlärningsmekanism som leder till en nödvändig åtgärd med tanke på sensordata, eller tvärtom.
Det besvärliga tredelade AI-systemet-varje del talar sitt eget språk-är ett långsamt sätt att få robotar att utföra sensomotoriska uppgifter. Nästa steg inom robotik blir att integrera en robots uppfattningar med dess motoriska förmågor. Denna fusion, känd som "aktiv uppfattning, "skulle ge ett mer effektivt och snabbare sätt för roboten att slutföra uppgifter.
I författarnas nya beräkningsteori, en robots operativsystem skulle baseras på hyperdimensionella binära vektorer (HBV), som finns i ett gles och extremt högdimensionellt utrymme. HBV kan representera olika diskreta saker - till exempel en enda bild, ett koncept, ett ljud eller en instruktion; sekvenser som består av diskreta saker; och grupper av diskreta saker och sekvenser. De kan redogöra för alla dessa typer av information på ett meningsfullt konstruerat sätt, binda varje modalitet tillsammans i långa vektorer av 1s och 0s med samma dimension. I detta system, handlingsmöjligheter, sensorisk inmatning och annan information upptar samma utrymme, är på samma språk, och är sammansmältade, skapa ett slags minne för roboten.
De Science Robotics papper är första gången som uppfattning och handling har integrerats.
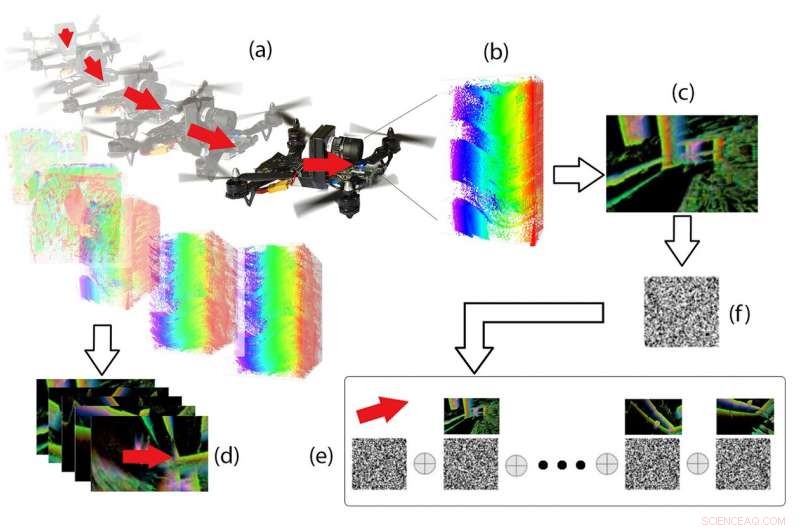
Hyperdimensionell pipeline. Från händelsedata (b) inspelade på DVS under drönare flygning (a), "Händelsebilder" (c) och 3D -rörelsevektorer (d) beräknas, och båda är kodade som binära vektorer och kombinerade i minnet via speciella vektoroperationer (e). Med tanke på en ny händelsebild (f), den tillhörande 3D -rörelsen kan återkallas från minnet. Kredit:Perception and Robotics Group, University of Maryland.
En hyperdimensionell ram kan förvandla valfri sekvens av "ögonblick" till nya HBV, och gruppera befintliga HBV:er tillsammans, alla i samma vektorlängd. Detta är ett naturligt sätt att skapa semantiskt betydelsefulla och informerade "minnen". Kodningen av mer och mer information leder i sin tur till "historia" -vektorer och förmågan att komma ihåg. Signaler blir vektorer, indexering översätts till minne, och lärande sker genom gruppering.
Robotens minnen av vad den har känt och gjort tidigare kan få den att förvänta sig framtidsuppfattning och påverka dess framtida handlingar. Denna aktiva uppfattning skulle göra det möjligt för roboten att bli mer autonom och bättre kunna utföra uppgifter.
"En aktiv uppfattare vet varför den vill känna, väljer sedan vad som ska uppfattas, och bestämmer hur, när och var man ska uppnå uppfattningen, "säger Aloimonos." Den väljer och fixerar på scener, stunder i tiden, och avsnitt. Sedan anpassar den sina mekanismer, sensorer, och andra komponenter för att agera utifrån vad den vill se, och väljer synpunkter för att bäst fånga upp vad det avser. "
"Vår hyperdimensionella ram kan hantera alla dessa mål."
Tillämpningar av Maryland -forskningen kan sträcka sig långt bortom robotik. Det slutliga målet är att kunna göra AI själv på ett fundamentalt annorlunda sätt:från koncept till signaler till språk. Hyperdimensionell beräkning skulle kunna ge en snabbare och mer effektiv alternativ modell till iterativa neuronella nätverks- och djupinlärnings -AI -metoder som för närvarande används i dataprogram, till exempel datavinning, visuellt igenkänning och översättning av bilder till text.
"Neurala nätverksbaserade AI-metoder är stora och långsamma, eftersom de inte kan komma ihåg, "säger Mitrokhin." Vår hyperdimensionella teorimetod kan skapa minnen, vilket kommer att kräva mycket mindre beräkning, och borde göra sådana uppgifter mycket snabbare och effektivare. "
Bättre rörelsedetektering är en av de viktigaste förbättringarna som behövs för att integrera en robots avkänning med dess handlingar. Att använda en dynamisk vision -sensor (DVS) istället för konventionella kameror för denna uppgift har varit en nyckelkomponent för att testa den hyperdimensionella beräkningsteorin.
Digitalkameror och datorsynstekniker fångar scener baserade på pixlar och intensiteter i ramar som bara existerar "i ögonblicket". De representerar inte rörelse väl eftersom rörelse är en kontinuerlig enhet.
En DVS fungerar annorlunda. Det "tar inte bilder" i vanlig bemärkelse, men visar en annan konstruktion av verkligheten som är anpassad för robotarnas syften som behöver hantera rörelser. Det fångar tanken på att se rörelse, särskilt kanterna på föremål när de rör sig. Även känd som en "kiselhinna, "den här sensorn inspirerad av däggdjurssyn registrerar asynkront ljusförändringar som sker vid varje DVS -pixel. Sensorn rymmer ett stort antal ljusförhållanden, från mörkt till ljust, och kan lösa mycket snabb rörelse med låg latens-idealiska egenskaper för realtidsapplikationer inom robotik, till exempel autonom navigering. Data som det samlar in är mycket bättre lämpade för den integrerade miljön i den hyperdimensionella beräkningsteorin.
En DVS registrerar en kontinuerlig ström av händelser, där en händelse genereras när en enskild pixel detekterar en viss fördefinierad förändring i logaritmen för ljusintensiteten. Detta uppnås genom analog krets som är integrerad på varje pixel, och varje händelse rapporteras med sin pixelplats och tidsstämpel för mikrosekundnoggrannhet.
"Data från denna sensor, händelse molnen, är mycket glesare än bildsekvenser, "säger Cornelia Fermüller, en av författarna till Science Robotics -papper. "Vidare, händelse molnen innehåller den viktiga informationen för kodning av utrymme och rörelse, konceptuellt konturerna i scenen och deras rörelse. "
Skivor av händelsemoln kodas som binära vektorer. Detta gör DVS till ett bra verktyg för att implementera teorin om hyperdimensionell beräkning för att smälta uppfattning med motoriska förmågor.
En DVS ser glesa händelser i tid, tillhandahålla tät information om förändringar i en scen, och möjliggör exakt, snabb och gles uppfattning om världens dynamiska aspekter. Det är en asynkron differentialsensor där varje pixel fungerar som en helt oberoende krets som spårar ljusets intensitetsförändringar. När detektering av rörelse verkligen är den typ av syn som behövs, DVS är det valda verktyget.