Kredit:arXiv:1905.09773 [cs.CV]
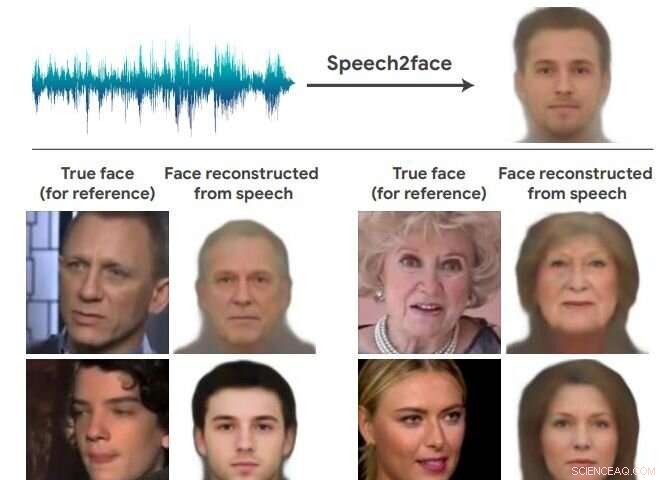
Ännu en gång, Artificiell intelligens-team retar det omöjligas rike och levererar överraskande resultat. Detta team i nyheterna kom på hur en persons ansikte kan se ut bara baserat på röst. Välkommen till Speech2Face. Forskargruppen hittade ett sätt att rekonstruera vissa människors mycket grova likhet baserat på korta ljudklipp.
Tidningen som beskriver deras arbete finns uppe på arXiv, och har titeln "Speech2Face:Learning the Face Behind a Voice." Författare är Tae-Hyun Åh, Tali Dekel, Changil Kim, Inbar Mosseri, William Freemany, Michael Rubinstein och Wojciech Matusiky. "Vårt mål i det här arbetet är att studera i vilken utsträckning vi kan sluta oss till hur en person ser ut utifrån hur de pratar."
De utvärderar och kvantifierar numeriskt hur, och på vilket sätt, deras Speech2Face-rekonstruktioner från ljud liknar högtalarnas verkliga ansiktsbilder.
Författarna ville tydligen se till att deras avsikt var tydlig, inte som ett försök att koppla samman röster med bilder av de specifika personer som faktiskt talade, som "vårt mål är inte att förutsäga en igenkännlig bild av det exakta ansiktet, utan snarare för att fånga dominerande ansiktsdrag hos personen som är korrelerade med inmatningstalet."
Författarna på GitHub sa att de också kände att det var viktigt att diskutera etiska överväganden i tidningen "på grund av den potentiella känsligheten hos ansiktsinformation."
De sa i sin tidning att deras metod "inte kan återställa en persons sanna identitet från deras röst (dvs. en exakt bild av deras ansikte). Detta beror på att vår modell är tränad för att fånga visuella egenskaper (relaterade till ålder, kön, etc.) som är gemensamma för många individer, och endast i fall där det finns tillräckligt starka bevis för att koppla dessa visuella egenskaper med röst-/talattribut i data."
De sa också att modellen kommer att producera genomsnittliga ansikten - endast genomsnittliga ansikten - med karakteristiska visuella egenskaper korrelerade med inmatningstalet.
Jackie Snow, Snabbt företag , skrev om deras metod. Snow sa att datamängden som de tog bestod av klipp från YouTube. Speech2Face tränades av forskare på videor från internet som visade människor prata. De skapade en neural nätverksbaserad modell som "lär sig röstegenskaper associerade med ansiktsdrag från videorna."
Snö tillagd, "Nu, när systemet hör ett nytt ljud, AI:n kan använda vad den har lärt sig för att gissa hur ansiktet kan se ut."
Neurohive diskuterade deras arbete:"Från videorna, de extraherar tal-ansikte-par, som matas in i två grenar av arkitekturen. Bilderna kodas till en latent vektor med hjälp av den förtränade ansiktsigenkänningsmodellen, medan vågformen matas in i en röstkodare i form av ett spektrogram, för att utnyttja kraften i konvolutionella arkitekturer. Den kodade vektorn från röstkodaren matas in i ansiktsavkodaren för att erhålla den slutliga ansiktsrekonstruktionen."
Man kan också få en exakt rapport om deras metod och hur de testade med en artikel om Packt :
"De sa att de ytterligare utvärderade och numeriskt kvantifierade hur deras Speech2Face rekonstruerar, erhåller resultat direkt från ljud, och hur den liknar högtalarnas sanna ansiktsbilder. För detta, de testade sin modell både kvalitativt och kvantitativt på AVSpeech-datasetet och VoxCeleb-dataset."
Hur kan deras resultat hjälpa verkliga applikationer? De sa, "vi tror att förutsägelse av ansiktsbilder direkt från rösten kan stödja användbara applikationer, som att koppla ett representativt ansikte till telefon-/videosamtal baserat på talarens röst."
Varför deras arbete är viktigt:Tänk mönster. "Tidigare forskning har utforskat metoder för att förutsäga ålder och kön utifrån tal, sa Snow, "men i det här fallet, forskarna hävdar att de också har upptäckt korrelationer med vissa ansiktsmönster också."
© 2019 Science X Network