Kredit:KTH The Royal Institute of Technology
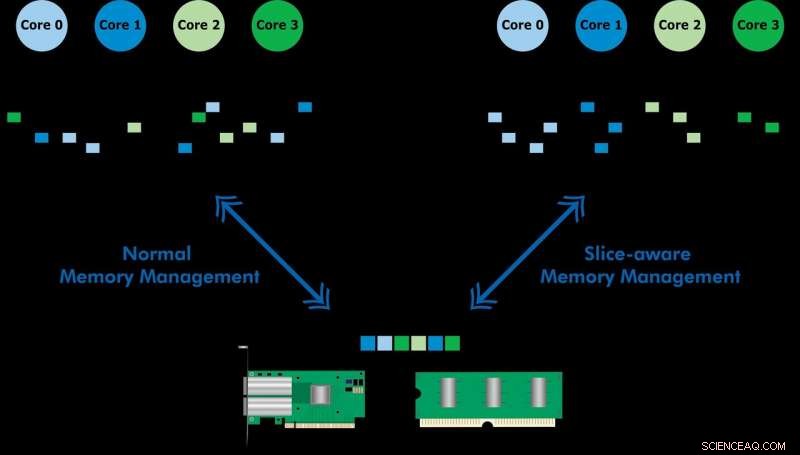
Utvecklad med Ericsson Research, Med den skivmedvetna minneshanteringsplanen kan ofta använda data nås snabbare via minnescachen (LLC) på en sista nivå på en Intel Xeon-processor. Genom att etablera en nyckelvärdesbutik och tilldela minne på ett sätt som det mappar till den lämpligaste LLC-skivan, de demonstrerade både höghastighetspaketbehandling och förbättrad prestanda för en nyckelvärdesbutik. Teamet använde det föreslagna systemet för att implementera ett verktyg som heter CacheDirector, vilket gör Data Direct I/O (DDIO) medveten om skivor och publicerade en konferensartikel, Få ut det mesta av Last Level Cache i Intel -processorer, som presenterades på EuroSys 2019 under våren.
"Just nu, en server som tar emot 64-byte-paket med 100 Gbps har bara 5,12 nanosekunder för att bearbeta varje paket innan nästa kommer, "säger medförfattaren Alireza Farshin, doktorand vid KTH:s Network Systems Laboratory. Men om data dirigeras till rätt cacheskiva i CPU:n, det kan nås snabbare - vilket möjliggör snabbare behandling av fler paket, på under 5 nanosekunder.
Data Direct I/O (DDIO) skickar paket till slumpmässiga skivor, vilket är långt ifrån effektivt. Med tanke på dagens icke-enhetliga cachearkitektur (NUCA), cache-hanteringslösningen är ovärderlig, säger KTH -professor Dejan Kostic, som ledde forskningen.
"I kombination med införandet av dynamiskt takhöjd i Data Plane Development Kit (DPDK), paketets rubrik kan placeras i segmentet av LLC som ligger närmast den relevanta processkärnan. Som ett resultat, kärnan kan komma åt paket snabbare samtidigt som kötiden minskar, " han säger.
"Vårt arbete visar att utnyttjandet av förbättringar av nanosekunder i latens kan ha stor inverkan på prestanda för applikationer som körs på redan optimerade datorsystem, "Säger Farshin. Teamet fann att för en CPU som körs på 3,2 GHz, CacheDirector kan spara upp till cirka 20 cykler per åtkomst till LLC vilket uppgår till 6,25 nanosekunder. Detta påskyndar paketbehandling och minskar svansfördröjningar för optimerade NFV -servicekedjor (Network Function Virtualization) med 100 Gbps med upp till 21,5 procent.