En algoritm följer bara regler utformade antingen direkt eller indirekt av en människa. Upphovsman:Shutterstock/Billion Photos
Algoritmernas roll i våra liv växer snabbt, från att helt enkelt föreslå sökresultat eller innehåll online i vårt sociala mediefoder, till mer kritiska frågor som att hjälpa läkare att bestämma vår cancerrisk.
Men hur vet vi att vi kan lita på en algoritms beslut? I juni, nästan 100 förare i USA lärde sig det hårda sättet att ibland kan algoritmer få det väldigt fel.
Google Maps fastnade för dem alla på en lerig privat väg i en misslyckad omväg för att undkomma en trafikstockning på väg till Denver International Airport, i Colorado.
När vårt samhälle blir alltmer beroende av algoritmer för råd och beslutsfattande, Det blir brådskande att ta itu med den taggiga frågan om hur vi kan lita på dem.
Algoritmer anklagas regelbundet för partiskhet och diskriminering. De har väckt oro från amerikanska politiker, bland påståenden har vi vita män som utvecklar algoritmer för ansiktsigenkänning som är utbildade att fungera bra endast för vita män.
Men algoritmer är inget annat än dataprogram som fattar beslut baserade på regler:antingen regler som vi gav dem, eller regler de räknade ut själva baserat på exempel vi gav dem.
I båda fallen, människor har kontroll över dessa algoritmer och hur de beter sig. Om en algoritm är bristfällig, det gör vi.
Så innan vi alla hamnar i en metaforisk (eller bokstavligen!) Lerig trafikstockning, Det finns ett brådskande behov av att återkomma till hur vi människor väljer att stresstesta dessa regler och vinna förtroende för algoritmer.
Algoritmer testas, ungefär
Människor är naturligtvis misstänkta varelser, men de flesta av oss kan övertygas av bevis.
Med tanke på tillräckligt många testexempel - med kända korrekta svar - utvecklar vi förtroende om en algoritm konsekvent ger rätt svar, och inte bara för enkla uppenbara exempel utan för de utmanande, realistiska och olika exempel. Då kan vi vara övertygade om att algoritmen är opartisk och pålitlig.
Låter lätt nog, höger? Men är det så här algoritmer brukar testas? Det är svårare än det låter att se till att testexempel är opartiska och representativa för alla möjliga scenarier som kan uppstå.
Mer vanligt, välstuderade jämförelseexempel används eftersom de är lätt tillgängliga från webbplatser. (Microsoft hade en databas med kändisansikten för att testa algoritmer för ansiktsigenkänning, men den raderades nyligen på grund av integritetsproblem.)
Jämförelse av algoritmer är också enklare när den testas på delade riktmärken, men dessa testexempel granskas sällan för deras fördomar. Ännu värre, algoritmernas prestanda rapporteras vanligtvis i genomsnitt över testexemplen.
Tyvärr, att veta att en algoritm fungerar bra i genomsnitt säger oss ingenting om vi kan lita på den i specifika fall.
Det är inte förvånande att läsa att läkare är skeptiska till Googles algoritm för cancerdiagnos, som ger 89% noggrannhet i genomsnitt. Hur vet en läkare om deras patient är en av de olyckliga 11% med en felaktig diagnos?
Med ökande efterfrågan på personlig medicin skräddarsydd för individen (inte bara Mr/Ms Average), och med medelvärden som är kända för att dölja alla möjliga synder, de genomsnittliga resultaten kommer inte att vinna mänskligt förtroende.
Behovet av nya testprotokoll
Det är uppenbarligen inte tillräckligt noggrant för att testa ett gäng exempel-välstuderade riktmärken eller inte-utan att bevisa att de är opartiska, och dra sedan slutsatser om en algoritms tillförlitlighet i genomsnitt.
Och ändå är det paradoxalt nog detta tillvägagångssätt som forskningslaboratorier runt om i världen är beroende av för att böja sina algoritmiska muskler. Den akademiska peer-review-processen förstärker dessa ärvda och sällan ifrågasatta testförfaranden.
En ny algoritm är publicerbar om den är bättre i genomsnitt än befintliga algoritmer på välstuderade riktmärkexempel. Om det inte är konkurrenskraftigt på detta sätt, det är antingen dolt från ytterligare granskning av granskningar, eller nya exempel presenteras för vilka algoritmen ser användbar ut.
På det här sättet, en varm, smickrande ljus lyser på varje nyutgiven algoritm, med litet försök att stresstesta dess styrkor och svagheter, och presentera det vårtor och allt. Det är datavetenskaplig version av medicinska forskare som inte publicerar de fullständiga resultaten av kliniska prövningar.
Eftersom algoritmiskt förtroende blir mer avgörande, vi måste snabbt uppdatera denna metod för att granska om de valda testexemplen är lämpliga för ändamålet. Än så länge, forskare har hållits tillbaka från striktare analys av bristen på lämpliga verktyg.
Vi har byggt ett bättre stresstest
Efter mer än ett decennium av forskning, mitt team har lanserat ett nytt online algoritmanalysverktyg som heter MATILDA:Melbourne Algorithm Test Instance Library med Data Analytics.
Det hjälper stresstestalgoritmer mer noggrant genom att skapa kraftfulla visualiseringar av ett problem, visar alla scenarier eller exempel en algoritm bör överväga för omfattande tester.
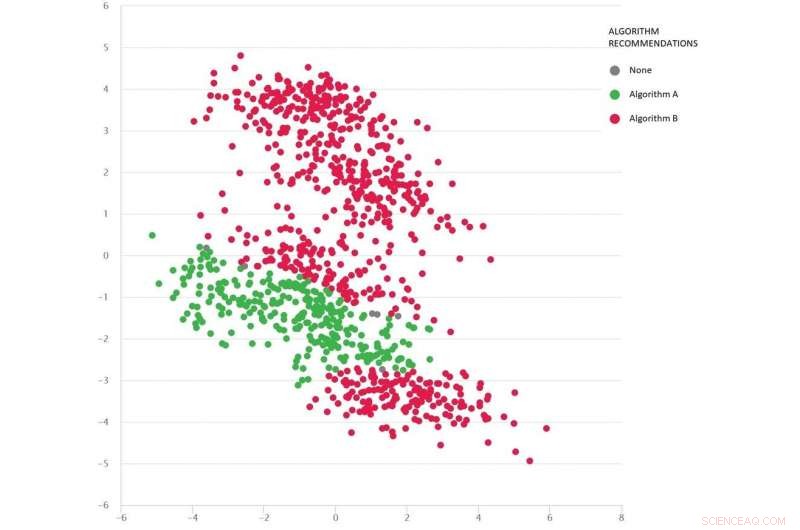
Ett problem av Google-maps-typ med olika testscenarier som prickar:Algoritm B (röd) är bäst i genomsnitt, men algoritm A (grön) är bättre i många fall. Upphovsman:MATILDA, Författare tillhandahålls
MATILDA identifierar varje algoritms unika styrkor och svagheter, rekommendera vilken av de tillgängliga algoritmerna som ska användas under olika scenarier och varför.
Till exempel, om det senaste regnet har gjort otätade vägar till lera, vissa algoritmer med "kortaste vägen" kan vara opålitliga om de inte kan förutse väderets troliga påverkan på restiderna när de rekommenderar den snabbaste vägen. Om inte utvecklare testar sådana scenarier kommer de aldrig att veta om sådana svagheter förrän det är för sent och vi har fastnat i leran.
MATILDA hjälper oss att se mångfalden och omfattningen av riktmärken, och där nya testexempel bör utformas för att fylla varje vrå i det möjliga utrymme där algoritmen kan bli ombedd att fungera.
Bilden nedan visar en mängd olika scenarier (prickar) för problem av typen Google Maps. Varje scenario varierar förhållanden - som ursprung och destinationsplatser, det tillgängliga vägnätet, väderförhållanden, restider på olika vägar-och all denna information fångas matematiskt samman och sammanfattas av varje scenarios tvådimensionella koordinater i rymden.
Två algoritmer jämförs (rött och grönt) för att se vilken som kan hitta den kortaste vägen. Varje algoritm har visat sig vara bäst (eller visat sig vara opålitlig) i olika regioner beroende på hur den fungerar i dessa testade scenarier.
Vi kan också göra en bra gissning om vilken algoritm som sannolikt är bäst för de saknade scenarierna (luckor) som vi ännu inte har testat.
Matematiken bakom MATILDA hjälper till att skapa denna visualisering, genom att analysera algoritmtillförlitlighetsdata från testscenarier, och hitta ett sätt att enkelt se mönstren.
Insikterna och förklaringarna innebär att vi kan välja den bästa algoritmen för problemet, snarare än att hålla tummarna och hoppas att vi kan lita på algoritmen som fungerar bäst i genomsnitt.
Genom att strikt testa algoritmer på detta sätt-vårtor och allt detta-bör vi minska risken för oseriösa algoritmbeslut, säkra förtroendet hos Mr/Ms Average, och kanske till och med de mest skeptiska människorna.
Denna artikel publiceras från The Conversation under en Creative Commons -licens. Läs originalartikeln.