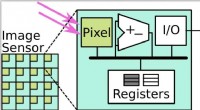
Blindljustransportfaktorisering med vår metod. De tre första sekvenserna projiceras på en vägg bakom kameran. Lego-sekvensen utförs live framför den upplysta väggen. Kredit:arXiv:1912.02314 [cs.CV]
Ett team av forskare visade att de kan återställa en video av rörelse som äger rum i en dold scen genom att observera förändringar i belysningen i en närliggande synlig region. De tittade på den indirekta effekten på skuggor och skuggning i ett observerat område.
Översättning:Att leka med skuggor för information kan vara mycket givande. Teamet av forskare skapade en ny AI-algoritm som kan hjälpa kameror att "se" saker utanför kameran med bara rörliga skuggor.
Deras metod kan rekonstruera en dold video baserat på skuggorna den kastar. Resultatet är att du kan uppskatta hur den dolda videon ser ut.
Hillary Grigonis in Digitala trender skrev om sin forskning med en intressant jämförelse — som att "läsa skuggdockor omvänt." Hur så? "...datorn ser den kaninformade skuggan och kan sedan skapa en uppskattning av objektet som skapade skuggan. Datorn vet inte vad objektet är, men kan ge en grov kontur av formen."
Börjar, de var intresserade av att lösa problemet med verksamhet utanför deras synfält.
Det finns mer information om projektwebbsidan för MIT CSAIL (Computer Science and Artificial Intelligence Laboratory) på compmirrors.csail.mit.edu och på GitHub.
Författarna ansåg värdet av sin forskning:"Vi har visat att röriga scener kan beräkningsmässigt förvandlas till lågupplösta speglar utan föregående kalibrering." Med bara en enda ingångsvideo av den synliga scenen, de kunde återställa en latent video av den dolda scenen såväl som en ljustransportmatris.
"Vi tycker att det är anmärkningsvärt, " sa de, "att bara fråga efter latenta faktorer som lätt kan uttryckas av ett CNN [konvolutionellt neuralt nätverk] är tillräckligt för att lösa vårt problem, så att vi helt kan kringgå utmaningar som uppskattningen av scenens geometri och reflektansegenskaper."
Postat den 6 december, deras video har titeln "Computational Mirrors:Revealing Hidden Video." Michael Zhang in PetaPixel sammanfattade vad de gjorde i videon. "Forskare vid MIT:s CSAIL delar med sig av hur de riktade en kamera mot en hög med föremål och sedan filmade skuggorna som skapades på dessa föremål av en person som rörde sig utanför kameran."
Videotexterna påpekade vidare att deras metod också kan rekonstruera silhuetten av en live-action-föreställning från dess skuggor. Resultaten täcker åtminstone färg och rörelse. Zhang bedömde vad de kunde göra. "AI:n analyserade skuggorna och kunde rekonstruera en suddig men slående exakt video av vad personen gjorde med sina [sic] händer."
Potentiella applikationer? Videoanteckningar:"Med ytterligare förfining, denna metod skulle kunna göra det möjligt för självkörande bilar att upptäcka dolda hinder.
Rachel Gordon, MIT CSAIL, talade om andra möjligheter:äldreomsorgscentra som ser till säkerheten för sina invånare; sök- och räddningsteam som använder sig av detta när de ska navigera i farliga och blockerade områden.
Allt som allt, forskarna har tagit en intressant väg mot att förstå information bortom synfältet, men andra vid MIT har på sätt och vis varit där, gjort det. Scener utanför en normal siktlinje var i fokus för MIT-forskare för sju år sedan, sa CSAILs Gordon, och de använde sedan lasrar för att producera 3D-bilder.
I den senaste forskningssatsningen, dock, teamet ville se vad de kunde uppnå utan någon speciell utrustning. Gordon citerade huvudforskaren om detta. Miika Aittala, vem sa, "Du kan uppnå en hel del med icke-line-of-sight bildbehandlingsutrustning som laser, men i vårt tillvägagångssätt har du bara tillgång till ljuset som naturligt når kameran, och du försöker få ut det mesta av den knappa informationen i den."
Tänk avkoda. Utmaningen var att avkoda och förstå dessa ljussignaler. Tänk algoritm. Gordon skrev att teamet fokuserade på att bryta tvetydigheten genom att specificera algoritmiskt att de ville ha ett "krypteringsmönster" som motsvarar sannolikt verklig skuggning och skuggning, för att avslöja den dolda videon som ser ut att ha kanter och föremål som rör sig koherent.
Hon förklarade att deras algoritm tränar två neurala nätverk samtidigt. "Ett nätverk producerar krypteringsmönstret, och den andra uppskattar den dolda videon. Nätverken belönas när kombinationen av dessa två faktorer återger videon som spelats in från röran, driver dem att förklara observationerna med rimliga dolda data."
Deras papper som diskuterar deras arbete heter "Computational Mirrors:Blind Inverse Light Transport by Deep Matrix Factorization, " och det finns på arXiv. Författare är Miika Aittala, Prafull Sharma, Lukas Murmann, Adam Yedidia, Gregory Wornell, William T. Freeman och Frédo Durand.
Rapporter sa att de skulle presentera sitt arbete på Conference on Neural Information Processing Systems (NeurIPS 2019) i Vancouver, British Columbia.
© 2019 Science X Network