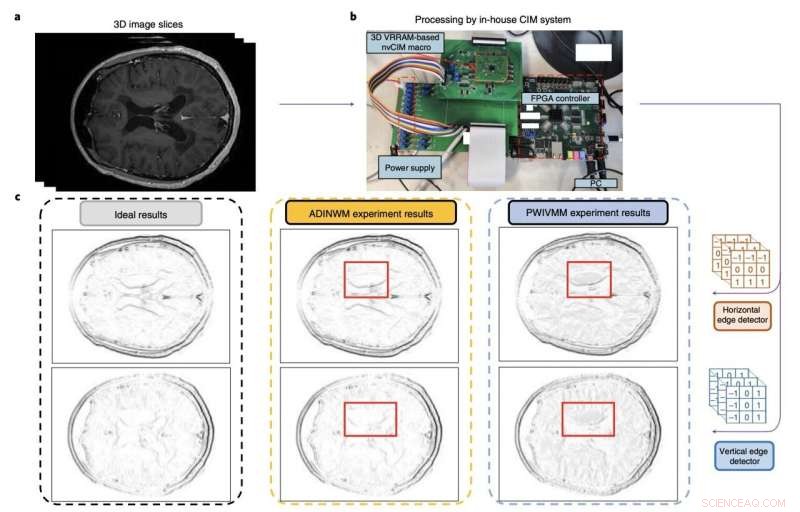
Figur som sammanfattar utvärderingen och prestandan för forskarnas computing-in-memory makro. Kredit:Huo et al (Nature Electronics , 2022).
Maskininlärningsarkitekturer baserade på konvolutionella neurala nätverk (CNN) har visat sig vara mycket värdefulla för ett brett spektrum av tillämpningar, allt från datorseende till analys av bilder och bearbetning eller generering av mänskligt språk. För att hantera mer avancerade uppgifter blir dock dessa arkitekturer allt mer komplexa och beräkningskrävande.
Under de senaste åren har många elektronikingenjörer över hela världen därför försökt utveckla enheter som kan stödja lagring och beräkningsmässig belastning av komplexa CNN-baserade arkitekturer. Detta inkluderar tätare minnesenheter som kan stödja stora mängder vikter (d.v.s. de träningsbara och icke-träningsbara parametrarna som beaktas av de olika lagren av CNN).
Forskare vid den kinesiska vetenskapsakademin, Beijing Institute of Technology och andra universitet i Kina har nyligen utvecklat ett nytt computing-in-memory-system som kan hjälpa till att köra mer komplexa CNN-baserade modeller mer effektivt. Deras minneskomponent, introducerad i en artikel publicerad i Nature Electronics , är baserad på icke-flyktiga datorer i minnet makron gjorda av 3D memristor arrayer.
"Att skala sådana system till 3D-matriser kan ge högre parallellitet, kapacitet och densitet för de nödvändiga vektor-matrismultiplikationsoperationerna", skrev Qiang Huo och hans kollegor i sin uppsats. "Men att skala till tre dimensioner är utmanande på grund av tillverknings- och enhetsvariabilitetsproblem. Vi rapporterar ett tvåkilobits icke-flyktigt beräknings-i-minne-makro som är baserat på ett tredimensionellt vertikalt resistivt slumpmässigt åtkomstminne tillverkat med en 55 nm komplementär metall-oxid-halvledarprocess."
Resistiva slumpmässiga minnen, eller RRAM, är icke-flyktiga (d.v.s. behåller data även efter avbrott i strömförsörjningen) lagringsenheter baserade på memristorer. Memristorer är elektroniska komponenter som kan begränsa eller reglera flödet av elektrisk ström i kretsar, samtidigt som de registrerar mängden laddning som tidigare flödat genom dem.
RRAM:er fungerar i huvudsak genom att variera motståndet över en memristor. Även om tidigare studier har visat den stora potentialen hos dessa minnesenheter, är konventionella versioner av dessa enheter separata från datormotorer, vilket begränsar deras möjliga tillämpningar.
Computing-in-memory RRAM-enheter designades för att övervinna denna begränsning genom att bädda in beräkningarna i minnet. Detta kan avsevärt minska överföringen av data mellan minnen och processorer, vilket i slutändan förbättrar det övergripande systemets energieffektivitet.
Beräkningsenheten i minnet skapad av Huo och hans kollegor är ett 3D RRAM med vertikalt staplade lager och perifera kretsar. Enhetens kretsar tillverkades med 55 nm CMOS-teknik, den teknik som ligger till grund för de flesta integrerade kretsar på marknaden idag.
Forskarna utvärderade sin enhet genom att använda den för att utföra komplexa operationer och för att köra en modell för att upptäcka kanter i MRT-hjärnskanningar. Teamet tränade sina modeller med två befintliga MRI-datauppsättningar för att träna bildigenkänningsverktyg, kända som MNIST- och CIFAR-10-datauppsättningarna.
"Vårt makro kan utföra 3D vektor-matris multiplikation operationer med en energieffektivitet på 8,32 tera-operationer per sekund per watt när ingångs-, vikt- och utdata är 8,9 respektive 22 bitar, och bittätheten är 58,2 bitar µm –2 ", skrev forskarna i sin uppsats. "Vi visar att makrot erbjuder mer exakt hjärn-MRI-kantdetektering och förbättrad slutledningsnoggrannhet på CIFAR-10-datauppsättningen än konventionella metoder."
I de första testerna uppnådde det vertikala RRAM-systemet för datoranvändning i minnet som skapats av Huo och hans kollegor anmärkningsvärda resultat, som överträffade konventionella RRAM-metoder. I framtiden kan det alltså visa sig vara mycket värdefullt för att köra komplexa CNN-baserade modeller mer energieffektivt, samtidigt som det möjliggör bättre noggrannhet och prestanda. + Utforska vidare
© 2022 Science X Network