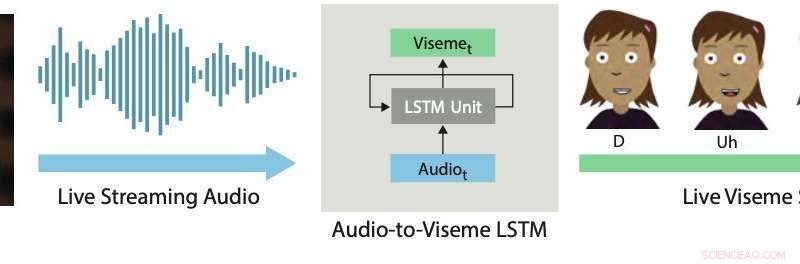
Läppsynkronisering i realtid. Vår djupinlärningsmetod använder en LSTM för att konvertera livestreamande ljud till diskreta visemes för 2D-karaktärer. Kredit:Aneja &Li.
Live 2D-animation är en ganska ny och kraftfull form av kommunikation som gör att mänskliga artister kan kontrollera seriefigurer i realtid samtidigt som de interagerar och improviserar med andra skådespelare eller medlemmar av en publik. Nya exempel inkluderar Stephen Colbert som intervjuar tecknade gäster på The Late Show , Homer svarar på inkommande frågor från tittare under ett avsnitt av Simpsons , Archer pratar med en livepublik på ComicCon, och Disneys stjärnor Star vs. The Forces of Evil och Min lilla ponny värd för livechattsessioner med fans via YouTube eller Facebook Live.
Att producera realistiska och effektiva live 2D-animationer kräver användning av interaktiva system som automatiskt kan omvandla mänskliga prestationer till animationer i realtid. En nyckelaspekt av dessa system är att uppnå en bra läppsynk, vilket i huvudsak betyder att munnen på animerade karaktärer rör sig på rätt sätt när de talar, efterlikna de rörelser som observeras i artisternas mun.
Bra läppsynkronisering kan göra live 2D-animation mer övertygande och kraftfull, låta animerade karaktärer förkroppsliga föreställningen mer realistiskt. Omvänt, dålig läppsynkronisering bryter vanligtvis illusionen av karaktärer som livedeltagare i en föreställning eller dialog.
I en tidning som nyligen förpublicerades den arXiv, två forskare vid Adobe Research och University of Washington introducerade ett djupinlärningsbaserat interaktivt system som automatiskt genererar live-läppsynk för animerade 2D-figurer i lager. Systemet som de utvecklade använder en modell för långtidsminne (LSTM), en arkitektur för återkommande neuralt nätverk (RNN) som ofta tillämpas på uppgifter som involverar klassificering eller bearbetning av data, samt göra förutsägelser.
"Eftersom tal är den dominerande komponenten i nästan alla liveanimationer, vi tror att det mest kritiska problemet att ta itu med i den här domänen är live läppsynkronisering, vilket innebär att omvandla en skådespelares tal till motsvarande munrörelser (dvs. visemesekvens) i den animerade karaktären. I det här arbetet, vi fokuserar på att skapa läppsynkronisering av hög kvalitet för live 2D-animering, " Wilmot Li och Deepali Aneja, de två forskarna som utförde forskningen, berättade för TechXplore via e-post.
Li är huvudforskare vid Adobe Research med en doktorsexamen. i datavetenskap som har bedrivit omfattande forskning med fokus på ämnen i skärningspunkten mellan datorgrafik och människa-datorinteraktion. Aneja, å andra sidan, avslutar för närvarande en Ph.D. i datavetenskap vid University of Washington, där hon är en del av Graphics and Imaging Lab.
Systemet utvecklat av Li och Aneja använder en enkel LSTM-modell för att konvertera strömmande ljudingång till en motsvarande visemesekvens med 24 bilder per sekund, med mindre än 200 millisekunders latens. Med andra ord, deras system låter en animerad karaktärs läppar röra sig på ett liknande sätt som en mänsklig användares läppar som talar i realtid, med mindre än 200 millisekunders fördröjning mellan rösten och läpprörelsen.
"I det här arbetet, vi gör två bidrag – identifiera lämplig funktionsrepresentation och nätverkskonfiguration för att uppnå toppmoderna resultat för live 2-D läppsynkronisering och utarbeta en ny förstärkningsmetod för att samla in träningsdata för modellen, " förklarade Li och Aneja.
"För handskrivande läppsynkronisering, professionella animatörer fattar stilistiska beslut om det specifika valet av visem och tidpunkten och antalet övergångar. Som ett resultat, utbildning av en enskild modell för allmänt ändamål är osannolikt tillräcklig för de flesta tillämpningar, " sa Li och Aneja. Dessutom, Det kan vara både dyrt och tidskrävande att skaffa märkt läppsynkdata för att träna modeller för djupinlärning. Professionella animatörer kan tillbringa fem till sju timmars arbete per minut av tal för att handförfatta visemesekvenser. Medveten om dessa begränsningar, Li och Aneja utvecklade en metod som kan generera träningsdata snabbare och mer effektivt.
För att träna sin LSTM-modell mer effektivt, Li och Aneja introducerade en ny teknik som utökar handskrivna träningsdata med hjälp av ljudtidsförvrängning. Denna dataförstärkningsprocedur uppnådde bra läppsynkronisering även när man tränade sin modell på en liten märkt dataset.
För att utvärdera effektiviteten av deras interaktiva system för att producera läppsynk i realtid, forskarna bad mänskliga tittare att betygsätta kvaliteten på liveanimationer som drivs av deras modell med de som produceras med kommersiella 2D-animeringsverktyg. De fann att de flesta tittare föredrog läppsynkroniseringen som genererades av deras tillvägagångssätt framför den som producerades av andra tekniker.
"Vi undersökte också kompromissen mellan läppsynkkvalitet och mängden träningsdata, och vi fann att vår dataförstärkningsmetod avsevärt förbättrar modellens produktion, " sa Li och Aneja. "I allmänhet, vi kan producera rimliga resultat med bara 15 minuters handskriven läppsynkdata."
Intressant, forskarna fann att deras LSTM-modell kan förvärva olika läppsynkroniseringsstilar baserat på data den tränas på, samtidigt som den generaliserar väl över ett brett spektrum av talare. Imponerad av de uppmuntrande resultaten som modellen uppnått, Adobe bestämde sig för att integrera en version av det i sin programvara Adobe Character Animator, släpptes hösten 2018.
"Exakt, läppsynkronisering med låg latens är viktig för nästan alla inställningar för liveanimering, och våra experiment med mänskligt omdöme visar att vår teknik förbättras på befintliga toppmoderna 2-D läppsynkmotorer, de flesta kräver offlinebearbetning, sa Li och Aneja. Alltså, forskarna tror att deras arbete har omedelbara praktiska konsekvenser för både direktsänd och icke-livande 2D-animation. Forskarna är inte medvetna om tidigare 2-D läppsynkroniseringsarbete med liknande omfattande jämförelser med kommersiella verktyg.
I deras senaste studie, Li och Aneja kunde ta itu med några av de viktigaste tekniska utmaningarna i samband med utvecklingen av tekniker för live 2D-animering. Först, de demonstrerade en ny metod för att koda konstnärliga regler för 2-D läppsynkronisering med RNN, som skulle kunna förbättras ytterligare i framtiden.
Forskarna tror att det finns många fler möjligheter att tillämpa moderna maskininlärningstekniker för att förbättra arbetsflöden för 2D-animering. "Än så länge, en utmaning har varit bristen på träningsdata, som är dyrt att samla in. Dock, som vi visar i detta arbete, det kan finnas sätt att utnyttja strukturerad data och automatiska redigeringsalgoritmer (t.ex. dynamisk tidsförvrängning) för att maximera användbarheten av handgjorda animationsdata, sa Li och Aneja.
Även om dataförstärkningsstrategin som föreslagits av forskarna avsevärt kan minska träningsdatakraven för modeller utformade för att producera läppsynk i realtid, Att handanimera tillräckligt med läppsynkroniseringsinnehåll för att träna nya modeller kräver fortfarande avsevärt arbete och ansträngning. Enligt Li och Aneja, dock, Det kan vara onödigt att träna om en hel modell från början för varje ny läppsynkstil den möter.
Forskarna är intresserade av att utforska finjusteringsstrategier som kan göra det möjligt för animatörer att anpassa modellen till olika stilar med en mycket mindre mängd användarinput. "En relaterad idé är att direkt lära sig en läppsynkroniseringsmodell som uttryckligen inkluderar justerbara stilistiska parametrar. Även om detta kan kräva en mycket större träningsdatauppsättning, den potentiella fördelen är en modell som är tillräckligt generell för att stödja en rad läppsynkroniseringsstilar utan ytterligare träning, " sa forskarna.
Intressant, i sina experiment, forskarna observerade att den enkla korsentropiförlusten de använde för att träna sin modell inte exakt återspeglade de mest relevanta perceptuella skillnaderna mellan läppsynksekvenser. Mer specifikt, de fann att vissa avvikelser (t.ex. saknar en övergång eller ersätter en sluten munvisem med en öppen munvisem) är mycket mer uppenbara än andra. "Vi tror att design eller inlärning av en perceptuell förlust i framtida forskning kan leda till förbättringar i den resulterande modellen, sa Li och Aneja.
© 2019 Science X Network