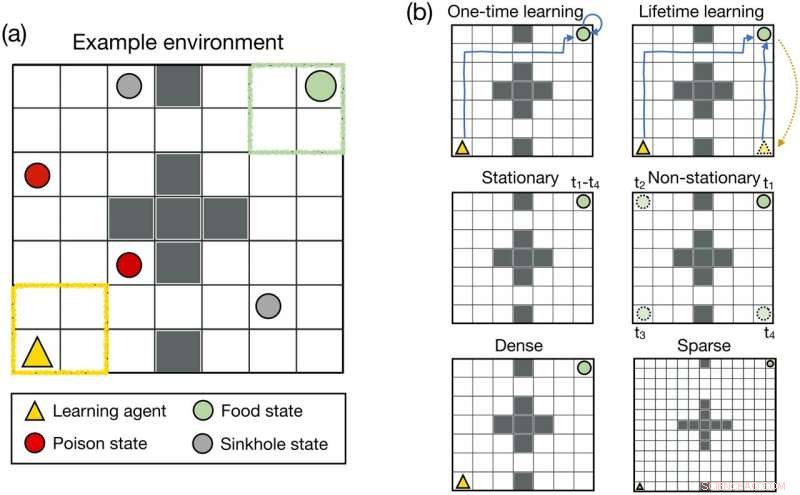
Miljödesign. (a) Den tvådimensionella gridworld-miljön som användes i experiment 1. (b) För att studera egenskaperna hos den optimala belöningen gjorde vi flera modifieringar av gridworld-miljön. Översta raden:I engångsinlärningsmiljön kunde agenten välja att stanna på matplatsen konstant efter att ha nått den. I livstidsinlärningsmiljön teleporterades agenten till en slumpmässig plats i rutnätsvärlden så snart den nådde mattillståndet. Mellersta raden:I den stationära miljön förblev maten på samma plats under agentens livstid. I den icke-stationära miljön ändrade maten sin plats under agentens livstid. Nedre raden:Vi använde en rutnätsvärld i storleken 7 × 7 för att simulera en tät belöningsinställning. För att simulera en sparsam belöningsinställning ökade vi storleken på rutnätsvärlden till 13 × 13. Kredit:PLOS Computational Biology (2022). DOI:10.1371/journal.pcbi.1010316
En trio av forskare, två med Princeton University, den andra Max Planck Institute for Biological Cybernetics, har utvecklat en förstärkningsinlärningsbaserad simulering som visar att människans önskan att alltid vilja ha mer kan ha utvecklats som ett sätt att påskynda inlärningen. I deras papper publicerat i PLOS Computational Biology med öppen tillgång , Rachit Dubey, Thomas Griffiths och Peter Dayan beskriver de faktorer som ingick i deras simuleringar.
Forskare som studerar mänskligt beteende har ofta blivit förbryllade över människors till synes motsägelsefulla önskningar. Många människor har en oupphörlig önskan om mer av vissa saker, även om de vet att det kanske inte leder till det önskade resultatet att möta dessa önskemål. Många vill ha mer och mer pengar, till exempel med tanken att mer pengar skulle göra livet lättare, vilket borde göra dem lyckligare. Men en mängd studier har visat att tjäna mer pengar sällan gör människor lyckligare (med undantag för de som börjar från en mycket låg inkomstnivå). I denna nya ansträngning försökte forskarna bättre förstå varför människor skulle ha utvecklats på detta sätt. För det ändamålet byggde de en simulering för att efterlikna hur människor reagerar känslomässigt på stimuli, som att uppnå mål. Och för att bättre förstå varför människor kan känna som de gör, lade de till kontrollpunkter som kunde användas som en lyckobarometer.
Simuleringen baserades på förstärkningsinlärning, där människor (eller en maskin) fortsätter att göra saker som erbjuder en positiv belöning och slutar göra saker som inte ger någon belöning eller en negativ belöning. Forskarna lade också till simulerade känslomässiga reaktioner på de kända negativa effekterna av tillvänjning och jämförelse, där människor blir mindre glada med tiden när de vänjer sig vid något nytt och blir mindre glada när de ser att någon annan har mer av något de vill ha.
När man körde simuleringen fann forskarna att den uppnådde mål snabbare när tillvänjning och jämförelse kom in – ett förslag på att sådana känslomässiga reaktioner också kan spela en roll för snabbare inlärning hos människor. De fann också att simuleringen blev mindre "glad" när den stod inför fler val när det gäller möjliga möjliga alternativ än när det bara fanns ett fåtal att välja mellan.
Forskarna föreslår att anledningen till att människor är benägna att bli instängda i en oändlig cykel av att alltid vilja ha mer är för att det totalt sett hjälper människor att lära sig snabbare. + Utforska vidare
© 2022 Science X Network