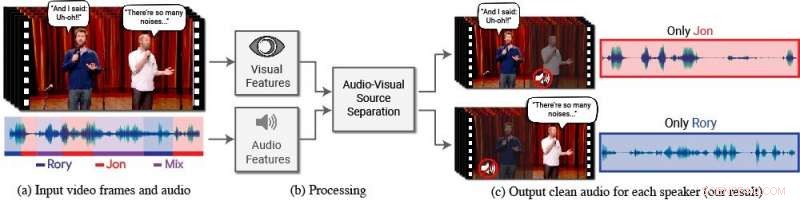
En ny modell isolerar och förbättrar talet för önskade högtalare i en video. (a) Ingången är en video (frames + ljudspår) med en eller flera personer som talar, där talet av intresse störs av andra talare och/eller bakgrundsljud. (b) Både ljud och visuella funktioner extraheras och matas in i en gemensam audiovisuell talseparationsmodell. (c) Utdata är en nedbrytning av det ingående ljudspåret till rena talspår, en för varje person som upptäcks i videon. Specifika personers tal förstärks i videorna medan allt annat ljud dämpas. Den nya modellen tränades med hjälp av tusentals timmars videosegment från teamets nya datauppsättning, AVSpeech, som kommer att släppas offentligt. Kredit:Författare/Google Video stillbilder:Med tillstånd av Team Coco/CONAN
Människor har en naturlig förmåga att fokusera på vad en enda person säger, även när det finns konkurrerande konversationer i bakgrunden eller andra störande ljud. Till exempel, människor kan ofta urskilja vad som sägs av någon på en fullsatt restaurang, under en bullrig fest, eller medan du tittar på tv-debatter där flera förståsigpåare pratar över varandra. Hittills, att beräkningsmässigt – och exakt – härma denna naturliga mänskliga förmåga att isolera tal har varit en svår uppgift.
"Datorer blir bättre och bättre på att förstå tal, men har fortfarande stora svårigheter att förstå tal när flera personer talar tillsammans eller när det är mycket ljud, säger Ariel Ephrat, en Ph.D. kandidat vid Hebrew University of Jerusalem-Israel och huvudförfattare till forskningen. (Ephrat utvecklade den nya modellen medan han arbetade på Google sommaren 2017.) "Vi människor vet hur man förstår tal under sådana förhållanden naturligt, men vi vill att datorer ska kunna göra det lika bra som vi, kanske ännu bättre."
För detta ändamål, Ephrat och hans kollegor på Google har utvecklat en ny audiovisuell modell för att isolera och förbättra talet för önskade talare i en video. Teamets djupa nätverksbaserade modell innehåller både visuella och auditiva signaler för att isolera och förbättra alla högtalare i vilken video som helst, även i utmanande verkliga scenarier, som videokonferenser, där flera deltagare ofta pratar samtidigt, och bullriga barer, som kan innehålla olika bakgrundsljud, musik, och konkurrerande samtal.
Laget, som inkluderar Googles Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T. Freeman, och Michael Rubinstein, kommer att presentera sitt arbete på SIGGRAPH 2018, hölls 12-16 augusti i Vancouver, British Columbia. Den årliga konferensen och utställningen visar upp världens ledande proffs, akademiker, och kreativa hjärnor i framkant av datorgrafik och interaktiva tekniker.
I det här arbetet, forskarna fokuserade inte bara på auditiva signaler för att skilja tal utan också visuella signaler i videon - dvs. försökspersonens läpprörelser och potentiellt andra ansiktsrörelser som kan bidra till vad han eller hon säger. De visuella funktionerna som samlas in används för att "fokusera" ljudet på en enda person som talar och för att förbättra kvaliteten på talseparation.
För att träna deras gemensamma audiovisuella modell, Ephrat och medarbetare kurerade en ny datauppsättning, "AVSpeech, "består av tusentals YouTube-videor och andra onlinevideosegment, som TED -samtal, instruktionsvideor, och högkvalitativa föreläsningar. Från AVSpeech, forskarna skapade en träningsuppsättning av så kallade "syntetiska cocktailpartyn" – blandningar av ansiktsvideor med rent tal och andra talljudspår med bakgrundsljud. För att isolera tal från dessa videor, användaren behöver bara ange ansiktet på personen i videon vars ljud ska pekas ut.
I flera exempel som beskrivs i tidningen, med titeln "Looking to Listen at the Cocktail Party:A Speaker-Oberoende Audio-Visual Model for Speech Separation, "den nya metoden gav överlägsna resultat jämfört med befintliga metoder endast för ljud på rena talblandningar, och betydande förbättringar när det gäller att leverera tydligt ljud från blandningar som innehåller överlappande tal och bakgrundsbrus i verkliga scenarier. Medan fokus för arbetet är talseparation och förbättring, lagets nya metod kan också tillämpas på automatisk taligenkänning (ASR) och videotranskription - dvs. dold textning på strömmande videor och TV. I en demonstration, den nya gemensamma audiovisuella modellen gav mer exakta bildtexter i scenarier där två eller flera högtalare var inblandade.
Till en början förvånad över hur väl deras metod fungerade, forskarna är entusiastiska över dess framtida potential.
"Vi har inte sett talseparation göras "in-the-wild" med sådan kvalitet tidigare. Det är därför vi ser en spännande framtid för denna teknik, " konstaterar Ephrat. "Det krävs mer arbete innan den här tekniken hamnar i konsumenternas händer, men med de lovande preliminära resultaten som vi har visat, vi kan säkert se att det stöder en rad applikationer i framtiden, som videotextning, videokonferenser, och till och med förbättrade hörapparater om sådana enheter kunde kombineras med kameror."
Forskarna undersöker för närvarande möjligheter att införliva det i olika Google-produkter.