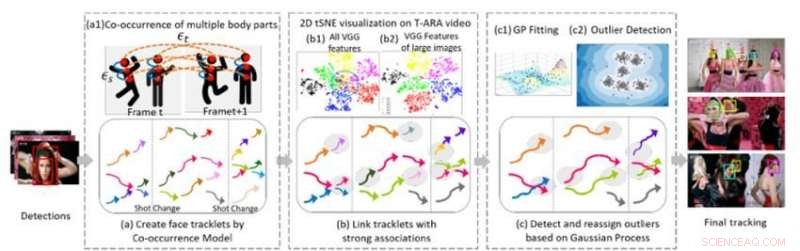
Figur 1. Tre kärnalgoritmiska komponenter i vår metod för multi-face tracking i en videosekvens. Kredit:IBM
Vid den senaste konferensen 2018 om datorseende och mönsterigenkänning, Jag presenterade en ny algoritm för spårning av flera ansikten, en viktig komponent för att förstå video. För att förstå visuella sekvenser som involverar människor, AI-system måste kunna spåra flera individer över scener, trots ändrade kameravinklar, belysning, och framträdanden. Den nya algoritmen gör det möjligt för AI-system att utföra denna uppgift.
Tidigare arbete inom detta område har till stor del fokuserat på att spåra en enskild person eller flera personer inom ett skott. Nästa steg är att spåra flera personer genom en hel video som består av många olika bilder. Den här uppgiften är utmanande eftersom människor kan lämna och gå in i videon igen upprepade gånger. Deras utseende kan förändras drastiskt tack vare garderoben, frisyr, och smink. Deras ställningar förändras, och deras ansikten kan vara delvis tilltäppta av betraktningsvinkeln, belysning, eller andra föremål på scenen. Kameravinkeln och zoomen ändras också, och egenskaper som dålig bildkvalitet, dålig belysning, och rörelseoskärpa kan öka svårigheten för uppgiften. Befintliga ansiktsigenkänningstekniker kan fungera i mer begränsade fall, där bilderna är av god kvalitet och visar en persons hela ansikte, men misslyckas i obegränsad video, där människors ansikten kan vara i profil, tilltäppt, beskuren, eller suddiga.
En metod för multi-face tracking
Samarbetar med professor Ying Hung, vid Institutionen för statistik och biostatistik vid Rutgers University, vi utvecklade en metod för att upptäcka olika individer i en videosekvens och känna igen dem om de går och sedan gå in i videon igen, även om de ser väldigt olika ut. Att göra detta, vi skapar först tracklets för personerna som är närvarande i videon. Tracklets är baserade på samtidig förekomst av flera kroppsdelar (ansikte, huvud och axlar, övre kroppen, och hela kroppen) så att människor kan spåras även när de inte är helt i sikte av kameran (t.ex. deras ansikten är bortvända eller tilltäppta av andra föremål). Vi formulerar flerpersonsspårningsproblemet som en grafstruktur G =(ν, ε) med två typer av kanter:εs och εt. Rumsliga kanter εs betecknar kopplingarna mellan olika kroppsdelar hos en kandidat inom en ram och används för att generera det hypotetiska tillståndet för en kandidat. Temporala kanter εt betecknar anslutningarna av samma kroppsdelar över intilliggande ramar och används för att uppskatta tillståndet för varje enskild person i olika ramar. Vi genererar face tracklets med hjälp av face-bounding boxes från varje enskild persons tracklets och extraherar ansiktsdrag för klustring.
Den andra delen av metoden kopplar ihop tracklets som tillhör samma person. Figur 1(b) visar 2-D tSNE-visualisering av extraherad VGG-ansiktsfunktion på en musikvideo. Det visar att jämfört med alla funktioner (b1), egenskaper hos stora bilder (b) är mer diskriminerande. Vi bygger entydiga kopplingar mellan tracklets genom att analysera objektens ansiktsbildupplösning och de relativa avstånden för extraherade djupa särdrag. Detta steg genererar ett initialt klustringsresultat. Empiriska studier visar att CNN-baserade modeller är känsliga för oskärpa och brus eftersom nätverken i allmänhet tränas på bilder av hög kvalitet. Vi genererar robusta slutliga klustringsresultat genom att använda en Gaussian Process (GP) modell för att kompensera för de djupa funktionsbegränsningarna och för att fånga datarikedomen. Till skillnad från CNN-baserade metoder, GP-modeller ger ett flexibelt parametriskt tillvägagångssätt för att fånga det underliggande systemets olinjäritet och rums-temporala korrelation. Därför, det är ett attraktivt verktyg som kan kombineras med det CNN-baserade tillvägagångssättet för att ytterligare minska dimensionen utan att förlora komplex och importera rumslig-temporal information. Vi tillämpar GP-modellen för att upptäcka extremvärden, ta bort anslutningarna mellan utstickare och andra spår, och sedan omtilldela extremvärdena till förfinade kluster som bildas efter att extremvärden har kopplats bort, vilket ger högkvalitativa kluster.
Spårning av flera ansikten i musikvideor
För att utvärdera resultatet av vårt tillvägagångssätt, vi jämförde det med state-of-the-art metoder för att analysera utmanande datauppsättningar av fria videor. I en serie experiment, vi använde musikvideor, som har hög bildkvalitet men betydande, snabba förändringar i scen, kamerainställning, kamerarörelser, smink, och tillbehör (som glasögon). Vår algoritm överträffade andra metoder med avseende på både klustringsnoggrannhet och spårning. Clusterrenheten var avsevärt bättre med vår algoritm jämfört med de andra metoderna (0,86 för vår algoritm mot 0,56 för närmaste konkurrent som använder en av musikvideorna). Dessutom, vår metod bestämde automatiskt antalet personer, eller kluster, att spåras utan behov av manuell videoanalys.
Spårningsprestandan för vår algoritm var också överlägsen toppmoderna metoder för de flesta mätvärden, inklusive återkallelse och precision. Vår metod ökade märkbart mest spårade (MT) och minskade instanser av identitetsbyte (IDS) och spårfragment (Frag). Videon nedan visar exempel på spårningsresultat i flera musikvideor. Vår algoritm spårar flera individer på ett tillförlitligt sätt över olika bilder i hela fria videor, även om vissa individer har väldigt lika ansiktsutseende, flera huvudsångare dyker upp i en rörig bakgrund fylld av publik, eller vissa ansikten är kraftigt tilltäppta. Detta ramverk för spårning av flera ansikten i obegränsad video är ett viktigt steg för att förbättra videoförståelsen. Algoritmen och dess prestanda beskrivs mer i detalj i vårt CVPR-dokument, "En tidigare-mindre metod för spårning av flera ansikten i videor utan begränsningar."
Den här historien återpubliceras med tillstånd av IBM Research. Läs originalberättelsen här.