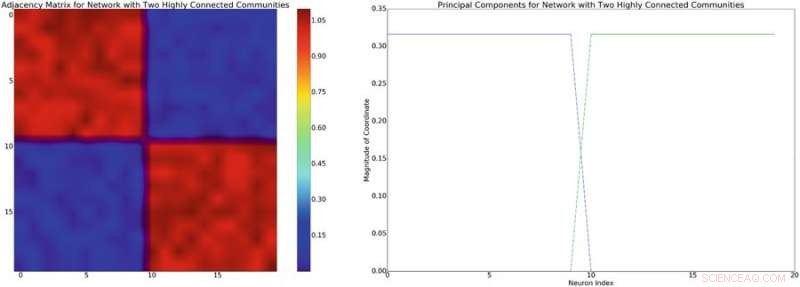
Vänster:exempel på en närliggande matris med ungefärlig block-diagonal struktur. Om man antar en linjär blandningsmodell av neuronala interaktioner, denna nätverksstruktur kommer att inducera en ungefär blockdiagonal kovarians av liknande struktur. Höger:de huvudsakliga komponenterna associerade med närliggande matris till vänster. Kredit:Mitchell &Petzold
Brian Mitchell och Linda Petzold, två forskare vid University of California, har nyligen tillämpat modellfritt djupförstärkningslärande på modeller av neural dynamik, uppnå mycket lovande resultat.
Förstärkningsinlärning är ett område för maskininlärning inspirerat av beteendepsychologi som tränar algoritmer för att effektivt slutföra särskilda uppgifter, använda ett system baserat på belöning och straff. En framstående milstolpe på detta område har varit utvecklingen av Deep-Q-Network (DQN), som ursprungligen användes för att träna en dator för att spela Atari -spel.
Modellfritt förstärkningslärande har tillämpats på en mängd olika problem, men DQN används i allmänhet inte. Den främsta anledningen till detta är att DQN kan föreslå ett begränsat antal åtgärder, medan fysiska problem i allmänhet kräver en metod som kan föreslå ett kontinuum av handlingar.
När du läser befintlig litteratur om neural kontroll, Mitchell och Petzold märkte den utbredda användningen av ett klassiskt paradigm för att lösa problem med neural kontroll med maskininlärningsstrategier. Först, ingenjören och försökspersonen är överens om målet och utformningen av deras studie. Sedan, den senare kör experimentet och samlar in data, som senare kommer att analyseras av ingenjören och användas för att bygga en modell av systemet av intresse. Till sist, ingenjören utvecklar en styrenhet för modellen och enheten implementerar denna styrenhet.
Resultat från experimentet som styr oscillation i fasutrymmet definierat av en enda huvudkomponent. Den första kurvan från toppen är en kurva över ingången till den aktiverade cellen över tiden; den andra tomten uppifrån är en tomt över spikarna i hela nätverket, där olika färger motsvarar olika celler; det tredje diagrammet från toppen motsvarar membranpotentialen för varje cell över tiden; den fjärde från det översta diagrammet visar målsvängningen; det nedre diagrammet visar den observerade svängningen. Policyn, trots att indata bara levereras till en enda cell, kan ungefär inducera målsvängningen i det observerade fasutrymmet. Upphovsman:Mitchell &Petzold 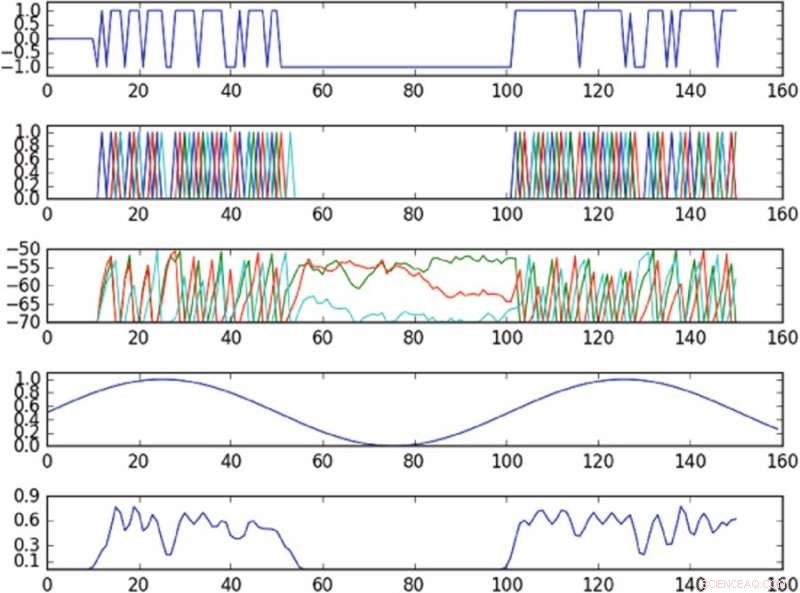
Forskarna anpassade en modellfri förstärkningsinlärningsmetod som kallas "deep deterministic policy gradients" (DDPG) och tillämpade den på modeller för neural dynamik på låg och hög nivå. De valde specifikt DDPG eftersom det erbjuder en mycket flexibel ram, vilket inte kräver att användaren modellerar systemdynamik.
Ny forskning har funnit att modellfria metoder i allmänhet kräver för mycket experiment med miljön, gör det svårare att tillämpa dem på mer praktiska problem. Ändå, forskarna fann att deras modellfria tillvägagångssätt fungerade bättre än nuvarande modellbaserade metoder och kunde lösa svårare problem med neural dynamik, såsom kontroll av banor genom ett latent fasrum i ett underaktiverat nätverk av neuroner.
"För de problem som vi behandlade i detta dokument, modellfria tillvägagångssätt var ganska effektiva och krävde inte mycket experiment alls, tyder på att för neurala problem, state-of-the-art kontroller är mer praktiskt användbara än folk kanske trodde, sa Mitchell.
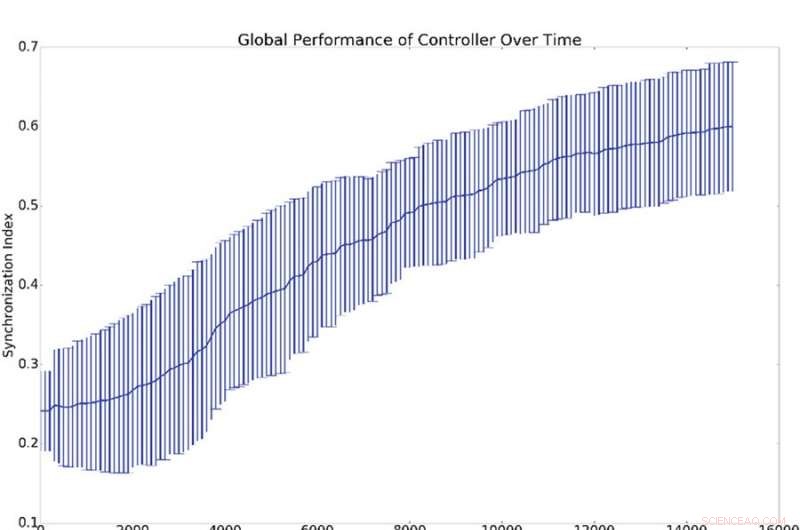
Sammanfattningsresultat av 10 synkroniseringsexperiment. (a) Avbildar medelvärdet och standardavvikelsen för den globala synkroniseringen, (dvs. q från ekvation 16), mot antalet kontrollperioder för den registeransvarige. (b) Visar histogram som visar synkroniseringsnivån för alla nätverksoscillatorer med referensoscillatorn (dvs qi från ekvation 16). Det är, en punkt på antingen de blå eller gröna kurvorna visar sannolikheten för att ha ett givet värde för qi. Det blå histogrammet visar antal före träning medan det gröna histogrammet visar antal efter träning. Den genomsnittliga synkroniseringen med referensen, qi, är mycket högre än global synkronisering, q, vilket förklaras av det faktum att synkronisering med referensen är lättare att inducera än global synkronisering. Upphovsman:Mitchell &Petzold
Mitchell och Petzold genomförde sin studie som en simulering, därför måste viktiga praktiska och säkerhetsaspekter övervägas innan deras metod kan introduceras inom kliniska miljöer. Ytterligare forskning som införlivar modeller i modellfria metoder, eller som sätter gränser för modellfria styrenheter, kan bidra till att öka säkerheten innan dessa metoder går in i kliniska miljöer.
I framtiden, forskarna planerar också att undersöka hur neurala system anpassar sig till kontroll. Mänskliga hjärnor är mycket dynamiska organ som anpassar sig till sin omgivning och förändras som svar på yttre stimulans. Detta kan orsaka en konkurrens mellan hjärnan och kontrollanten, särskilt när deras mål inte är i linje.
"I många fall, vi vill att controllern ska vinna och designen av controllers som alltid vinner är ett viktigt och intressant problem, sade Mitchell. Till exempel, i det fall där vävnaden som kontrolleras är en sjuk region i hjärnan, denna region kan ha en viss progression som styrenheten försöker korrigera. I många sjukdomar, denna progression kan motstå behandling (t.ex. en tumör som anpassar sig till utvisning av kemoterapi är ett kanoniskt exempel), men nuvarande modellfria tillvägagångssätt anpassar sig inte bra till den här typen av förändringar. Att förbättra modellfria kontroller för att bättre hantera anpassning från hjärnans sida är en intressant riktning som vi tittar på. "
Forskningen är publicerad i Vetenskapliga rapporter .
© 2018 Tech Xplore