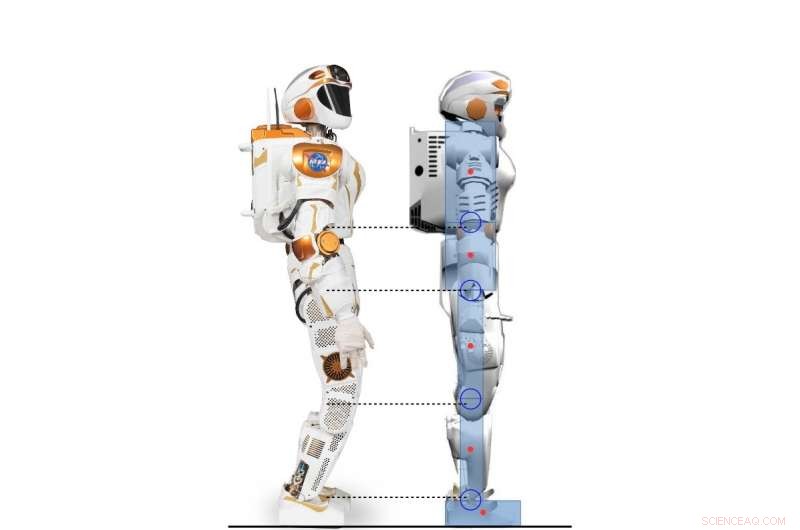
Sidovy av Valkyrie-roboten och den 2D-humanoida karaktären modellerad enligt Valkyrie-roboten. Kredit:Yang, Komura &Li
Forskare vid University of Edinburgh har utvecklat ett hierarkiskt ramverk baserat på deep reinforcement learning (RL) som kan förvärva en mängd olika strategier för humanoid balanskontroll. Deras ramar, beskrivs i ett dokument som förpublicerats på arXiv och presenterades vid 2017 års internationella konferens om humanoid robotik, skulle kunna utföra mycket mer människoliknande balansbeteenden än konventionella kontroller.
När du står eller går, Människor använder medfödd och effektivt ett antal tekniker för underaktiverad kontroll som hjälper dem att hålla balansen. Dessa inkluderar tålutning och hälrullning, vilket skapar bättre fot-markfrigång. Att replikera liknande beteenden i humanoida robotar kan avsevärt förbättra deras motor- och rörelseförmåga.
"Vår forskning fokuserar på att använda djup RL för att lösa dynamisk förflyttning av humanoida robotar, "Dr Zhibin Li, en föreläsare i robotik och kontroll vid University of Edinburgh, vem som genomförde studien, berättade för TechXplore. "Förr, förflyttning gjordes huvudsakligen med hjälp av konventionella analytiska metoder - modellbaserade, som är begränsade eftersom de kräver mänsklig ansträngning och kunskap, och kräver hög datorkraft för att köra online."
Kräver mindre mänsklig ansträngning och manuell inställning, maskininlärningstekniker kan leda till utvecklingen av mer effektiva och specifika styrenheter än traditionella tekniska metoder. En ytterligare fördel med att använda RL är att beräkningen för dessa verktyg också kan läggas ut offline, vilket resulterar i snabbare onlineprestanda för högdimensionella styrsystem, som humanoida robotar.

En simulerad Valkyrie-robot i tå-/hällutningsställning. Kredit:Yang, Komura &Li
"Med tanke på de allt kraftfullare djupa RL-algoritmerna, ett ökande antal forskningsstudier har börjat använda djup RL för att lösa kontrolluppgifter, eftersom de senaste framstegen inom djupa RL-algoritmer utformade för kontinuerliga aktionsdomäner har fört fram möjligheten att tillämpa förstärkningslärande kontinuerliga kontrolluppgifter som involverar komplicerad dynamik, "Dr. Li förklarade. "Huvudsyftet med vår forskning var att utforska möjligheterna att använda djup förstärkningsinlärning för att skaffa mångsidiga kontrollpolicyer som är jämförbara eller bättre än analytiska tillvägagångssätt samtidigt som man använder mindre mänsklig ansträngning."
Ramverket utvecklat av Dr Li, i samarbete med Dr. Taku Komura och Ph.D. student Chuanyu Yang, använder djup RL för att uppnå kontrollpolicyer på hög nivå. Får ständigt feedback om robotens tillstånd, dessa strategier möjliggör önskade ledvinklar vid en lägre frekvens.
"På låg nivå, proportionella och derivativa (PD) kontroller används vid en mycket högre kontrollfrekvens för att garantera stabila ledrörelser, " Doktoranden Chuanyu sa. "Ingångarna för PD-styrenheten på låg nivå är önskade ledvinklar som produceras av det neurala nätverket på hög nivå, och utgångarna är de önskade vridmomenten för ledmotorer."
Forskarna testade prestandan för sin algoritm och uppnådde mycket lovande resultat. De fann att överföring av mänsklig kunskap från kontrollteknikmetoder till belöningsdesignen för RL-algoritmer möjliggjorde balanskontrollstrategier som liknade de som används av människor. Dessutom, när RL-algoritmer förbättras genom en trial and error process, automatiskt anpassa sig till nya situationer, deras ramverk kräver lite handjustering eller andra ingrepp från mänskliga ingenjörer.
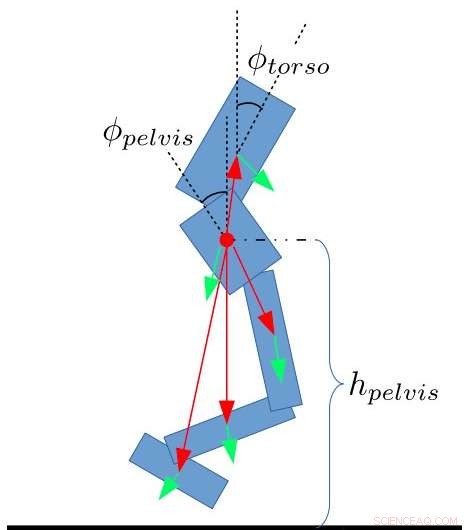
Ange egenskaper för tvåbenta. Yang, Komura &Li
"Vår studie visar att djup förstärkningsinlärning kan vara ett kraftfullt verktyg för att producera jämförbara balanseringsresultat som för en mänskligt konstruerad styrenhet med mindre manuell inställningsansträngning och kortare tid, "Dr Li sa. "Den djupförstärkande inlärningsalgoritmen vi utvecklade är till och med kapabel att lära sig uppkomna mänskliga beteenden som att luta runt tår eller hälar, som de flesta tekniska metoder inte kan utföra."
Dr. Li och hans kollegor arbetar nu med en förlängning av sin studie som tillämpar RL på en helkroppsrobot Valkyrie i en 3D-simulering. I denna nya forskningssatsning, de kunde generalisera balanseringsstrategier som liknar människan till promenader och andra rörelseuppgifter.
"Så småningom, vi skulle vilja tillämpa detta hierarkiska ramverk för att kombinera maskininlärning och robotkontroll på riktiga humanoida robotar, såväl som till andra robotplattformar, " sa Dr Li.
© 2018 Tech Xplore