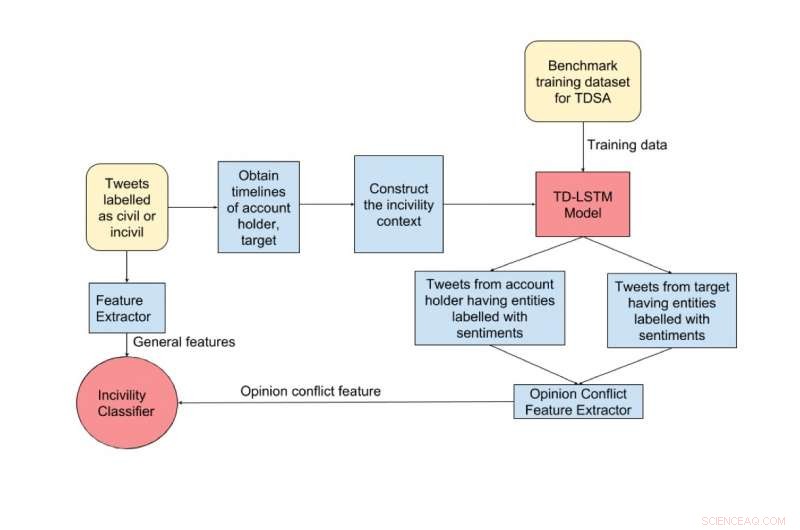
Schematisk över stegen för incivilitydetektering. De gulfärgade blocken representerar ingångar, de rödfärgade blocken representerar klassificerarna och de blåfärgade blocken representerar de mellanliggande stegen. Kredit:Maity et al.
Forskare vid Northwestern University, McGill University, och Indian Institute of Technology Kharagpur har nyligen utvecklat en CNN-modell (convolutional neural network) som kan hjälpa till att upptäcka kränkande inlägg på Twitter. Denna modell visade sig överträffa flera baslinjemetoder, uppnå en noggrannhet på 93,3 procent.
På senare år har kränkande beteende på onlineplattformar har ökat exponentiellt, särskilt på Twitter. Sociala medieföretag söker därför effektiva nya metoder för att identifiera detta beteende för att ingripa och förhindra att det orsakar allvarlig skada.
"Twitter, som ursprungligen var tänkt som ett torg för e-staden, ' förvandlas till en mosh-grop, "Animesh Mukherjee, en av forskarna som genomförde studien, berättade Tech Xplore . "Ett ökande antal cyberangrepp, fall av nätmobbning och incivilitet rapporteras varje dag, många av dem påverkar användarna allvarligt. Faktiskt, detta är en av huvudorsakerna till att Twitter tappar sin aktiva följare."
Onlineinnehåll kan spridas snabbt och nå en mycket bred publik, så fall av onlinemissbruk drar ofta ut på tiden under långa perioder med mycket skadliga effekter. Offret eller offren, såväl som andra känsliga åskådare, kan sluta med att läsa gärningsmannens ord otaliga gånger innan dessa slutligen försvinner från Twitter. Det är därför det är viktigt för sociala medieplattformar att upptäcka detta innehåll effektivt och snabbt, utföra snabba ingrepp för att ta bort det.
"Vi satte igång med målet att utveckla en mekanism som automatiskt kan upptäcka uncivila tweets tidigt, innan de kan göra allvarlig skada, " sade Mukherjee. "Vi observerade att oftast, ett offer/mål attackeras efter att ha uttryckt starka känslor mot vissa namngivna enheter. Detta ledde oss till den centrala idén att utnyttja åsiktskonflikter för att upptäcka uncivila tweets."
Mukherjee och hans kollegor insåg att kränkande inlägg ofta är korrelerade med åsiktsskillnader mellan gärningsmannen och målet, särskilt åsikter om en känd offentlig person eller enhet. De införlivade därför enhetsspecifik sentimentinformation i sin CNN-modell, hoppas att detta skulle förbättra dess prestanda när det gäller att upptäcka otillåtet innehåll.

I exemplet på incivility sammanhang som citeras nedan, vi observerar att målet twittrar positivt om Donald Trump och USA:s ekonomi. Dock, gärningsmannen (kontoinnehavaren) twittrar negativt om Trump och positivt om president Obama. Vi kan observera att det finns en åsiktskonflikt mellan målet och kontoinnehavaren eftersom känslorna som uttrycks mot den gemensamma namngivna enheten Donald Trump är motsatta. Gå igenom hela meddelandeutbytet, vi finner att denna åsiktskonflikt så småningom leder till en okivil post. Kredit:Maity et al.
"Teckennivån CNN försöker automatiskt extrahera mönster från uncivila tweets som skiljer dem från andra tweets, "Pawan Goyal, en annan forskare som utförde studien, berättade för Tech Xplore. "Vi valde också att använda inbäddning på karaktärsnivå, snarare än inbäddning på ordnivå. Eftersom tweets vanligtvis är små, innehåller bara några få ord, och har många stavningsvariationer, modeller på teckennivå har visat sig vara mer robusta än modeller på ordnivå."
Denna CNN-modell på teckennivå överträffade den bästa baslinjemetoden med 4,9 procent, uppnå en noggrannhet på 93,3 procent när det gäller att upptäcka uncivila tweets. Forskarna genomförde också en post-hoc-analys, ta en närmare titt på beteendeaspekter hos förövare och offer på Twitter, i hopp om att bättre förstå incivility incidenter.
Denna analys avslöjade att en betydande del av användarna var upprepade brottslingar som hade trakasserat mål över 10 gånger. Liknande, några mål hade trakasserats av olika gärningsmän vid flera olika tillfällen. "Det mest intressanta resultatet av den här studien är att åsiktskonflikter starkt korrelerar med uncivilt beteende på Twitter, "Mukherjee sa. "Denna enstaka funktion kopplad till den char-CNN-baserade djupa neurala modellen kan vara mycket effektiv för att identifiera uncivila tweets tidigt."
I framtiden, CNN-modellen utarbetad av Mukherjee och hans kollegor kan bidra till att motverka och minska kränkande innehåll på Twitter. Forskarna försöker nu utveckla liknande modeller för att upptäcka hatretorik på Twitter, såväl som på andra sociala medieplattformar.
"Under tiden, vi studerar också hur hatretorik sprids på sociala medier, samt att undersöka hur olika metoder för att motverka hatretorik kan hjälpa till att ta itu med detta onda onlinefenomen, " sa Mukherjee.
© 2018 Tech Xplore