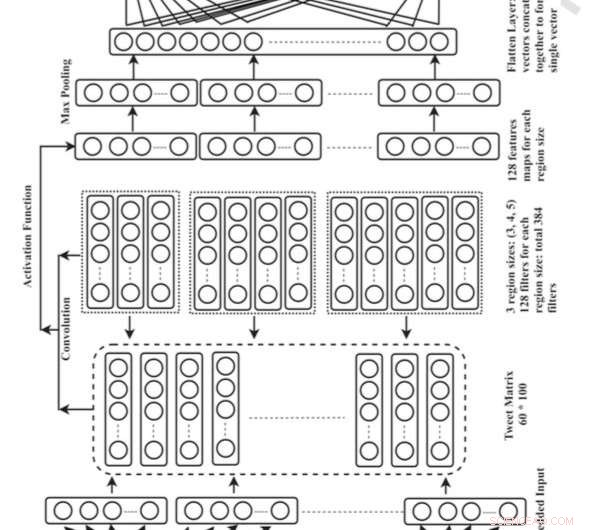
Övergripande arkitektur för Convolutional Neural Network (CNN). Kredit:Singh och Kumar.
Forskare vid National Institute of Technology Patna, i Indien, har nyligen tagit fram ett verktyg för att identifiera den geografiska platsen för nödsituationer och katastrofer, såväl som för de personer som är involverade i dem. Deras tillvägagångssätt, beskrivs i ett papper i International Journal of Disaster Risk Reduction , extraherar platsinformation från tweets med hjälp av en konvolutionell neuralt nätverk (CNN) -baserad modell.
"Under nödsituationer, den geografiska platsinformationen för händelserna, såväl som för berörda användare, är oerhört viktiga, " Jyoti Prakash Singh, en av forskarna som genomförde studien, berättade TechXplore. "Att identifiera denna geografiska plats är en utmanande uppgift, eftersom tillgängliga platsfält som användarplats och tweets platsnamn inte är tillförlitliga. Användarnas exakta GPS -plats är sällsynt i tweets, och även ibland felaktig i termer av rumslig information."
Människor som drabbats av naturkatastrofer eller andra nödsituationer delar ofta sin plats på sociala medier, Ber om hjälp. Denna information kan hjälpa insatsenheter och lokala myndigheter att upptäcka händelser tidigt, hitta offer och hjälpa dem. Dock, extrahera platsrelaterade data från tweets är en mycket utmanande uppgift, eftersom dessa ofta är skrivna på icke-standardiserade engelska och innehåller grammatiska fel, stavfel eller förkortningar.
"Det är nästan omöjligt för mänskliga operatörer som spårar tweets att gå igenom varje tweet och hitta platsinformationen som nämns i dem, ", sa Singh. "Detta motiverade oss att utveckla en lösning för att automatiskt extrahera platsinformation från tweets som ber om hjälp. I det här arbetet, vi använde djupinlärning för att avgöra om en tweet innehåller platsnamn och markera dessa ord."
Singh och hans kollega Abhivan Kumar utvecklade en CNN -modell som kan identifiera användarnas plats genom att analysera innehållet i deras tweets. De valde denna specifika djupinlärningsmetod eftersom den automatiskt kan lära sig den bästa representationen av indata och använda denna för att identifiera platsreferenser.
"Vi använde en inbäddningsteknik för att representera tweets vid ingångsskiktet i CNN och platsreferenser som finns i tweeten representeras i utmatningsskiktet i form av en noll-en-vektor, "Singh förklaras." Platsorden är kodade som 1 och orden utan plats kodas som 0. Vi använde flera kombinationer av 2 gram, 3 gram, 4 gram, och 5-gram filter för att extrahera funktioner från tweet. Efter att ha tränat för modellen för de 100 epokerna, den kan förutsäga platsreferenserna som nämns i tweeten med imponerande noggrannhet."
I en första utvärdering, CNN-modellen utarbetad av Singh och Kumar kunde extrahera alla platsrelaterade ord från tweets med mycket hög noggrannhet, även när texten i en tweet var bullrig. Forskarna testade sin modell på tweets som inte hade förbehandlats och innehöll grammatiska fel, stavfel, förkortningar, och andra störande faktorer.
"Den huvudsakliga praktiska innebörden av vårt arbete är att det lätt kan föras i pipeline, med hjälp av händelsedetekteringsmodeller, "Singh sa. "Händelsedetekteringsmodeller kan identifiera tweets som är relaterade till nämnda katastrof och vår modell kan extrahera platsen för offren som drabbats av den katastrofen."
I framtiden, CNN -modellen som utvecklats av forskarna kan hjälpa till att snabbt hitta nödsituationer och personer som behöver akut hjälp. Samma tillvägagångssätt kan också tillämpas på civila oroligheter, riktad reklam, observera regionalt mänskligt beteende, realtidstrafikledning och andra platsbaserade tjänster.
"I det här arbetet tog vi bara hänsyn till engelska tweets, men under en kris postar användare också tweets på sina regionala språk, ", sa Singh. "Vi arbetar därför på en modell som tar itu med denna flerspråkiga begränsning, samtidigt som man försöker utveckla en semi-övervakad modell för att minska frågan om datamärkning."
© 2018 Science X Network