Ett "computer vision"-system utvecklat vid UCLA kan identifiera objekt baserat på endast partiella glimtar, som genom att använda dessa fotoutdrag av en motorcykel. Kredit:University of California, Los Angeles
Ingenjörer från UCLA och Stanford University har demonstrerat ett datorsystem som kan upptäcka och identifiera de verkliga objekten det "ser" baserat på samma metod för visuell inlärning som människor använder.
Systemet är ett framsteg inom en typ av teknik som kallas "datorseende, " som gör det möjligt för datorer att läsa och identifiera visuella bilder. Det kan vara ett viktigt steg mot allmänna artificiella intelligenssystem - datorer som lär sig på egen hand, är intuitiva, fatta beslut utifrån resonemang och interagera med människor på ett mycket mer mänskligt sätt. Även om nuvarande AI-datorvisionssystem blir allt kraftfullare och mer kapabla, de är uppgiftsspecifika, vilket betyder att deras förmåga att identifiera vad de ser begränsas av hur mycket de har tränats och programmerats av människor.
Även dagens bästa datorseendesystem kan inte skapa en fullständig bild av ett objekt efter att bara ha sett vissa delar av det – och systemen kan luras genom att se objektet i en obekant miljö. Ingenjörer siktar på att göra datorsystem med dessa förmågor – precis som människor kan förstå att de tittar på en hund, även om djuret gömmer sig bakom en stol och bara tassarna och svansen syns. Människor, självklart, kan också lätt intuita var hundens huvud och resten av dess kropp är, men den förmågan undviker fortfarande de flesta artificiella intelligenssystem.
Dagens datorseendesystem är inte utformade för att lära sig på egen hand. De måste utbildas i exakt vad de ska lära sig, vanligtvis genom att granska tusentals bilder där objekten de försöker identifiera är märkta för dem. Datorer, självklart, kan inte heller förklara deras logik för att bestämma vad objektet på ett foto representerar:AI-baserade system bygger inte en intern bild eller en sunt förnuftsmodell av inlärda objekt som människor gör.
Ingenjörernas nya metod, beskrivs i Proceedings of the National Academy of Sciences , visar en väg kring dessa brister.
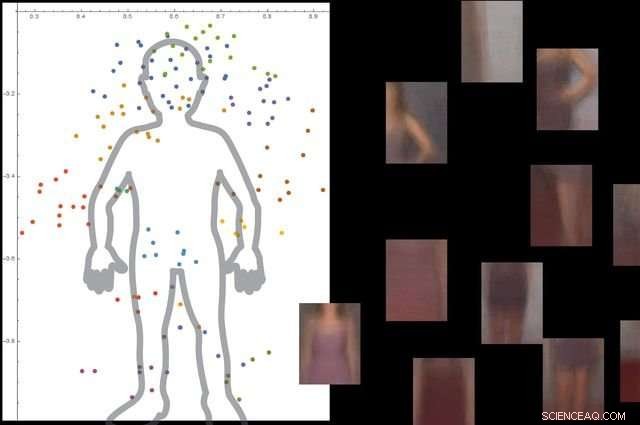
Systemet förstår vad en människokropp är genom att titta på tusentals bilder med människor i dem, och sedan ignorera icke -väsentliga bakgrundsobjekt. Kredit:University of California, Los Angeles
Tillvägagångssättet består av tre breda steg. Först, systemet delar upp en bild i små bitar, som forskarna kallar "viewlets". Andra, datorn lär sig hur dessa vyer passar ihop för att bilda objektet i fråga. Och slutligen, den tittar på vilka andra föremål som finns i det omgivande området, och huruvida information om dessa objekt är relevant för att beskriva och identifiera det primära objektet.
För att hjälpa det nya systemet att "lära sig" mer som människor, ingenjörerna bestämde sig för att fördjupa den i en internetkopia av miljön människor lever i.
"Lyckligtvis, Internet tillhandahåller två saker som hjälper ett hjärninspirerat datorseendesystem att lära sig på samma sätt som människor gör, sa Vwani Roychowdhury, en UCLA-professor i elektro- och datateknik och studiens huvudutredare. "Det ena är en mängd bilder och videor som visar samma typer av objekt. Det andra är att dessa objekt visas från många perspektiv - dolda, fågelöga, på nära håll - och de är placerade i alla olika typer av miljöer."
För att utveckla ramverket, forskarna hämtade insikter från kognitiv psykologi och neurovetenskap.
"Från och med som spädbarn, vi lär oss vad något är eftersom vi ser många exempel på det, i många sammanhang, " sa Roychowdhury. "Att kontextuellt lärande är en nyckelfunktion i våra hjärnor, och det hjälper oss att bygga robusta modeller av objekt som är en del av en integrerad världsbild där allt är funktionellt kopplat."
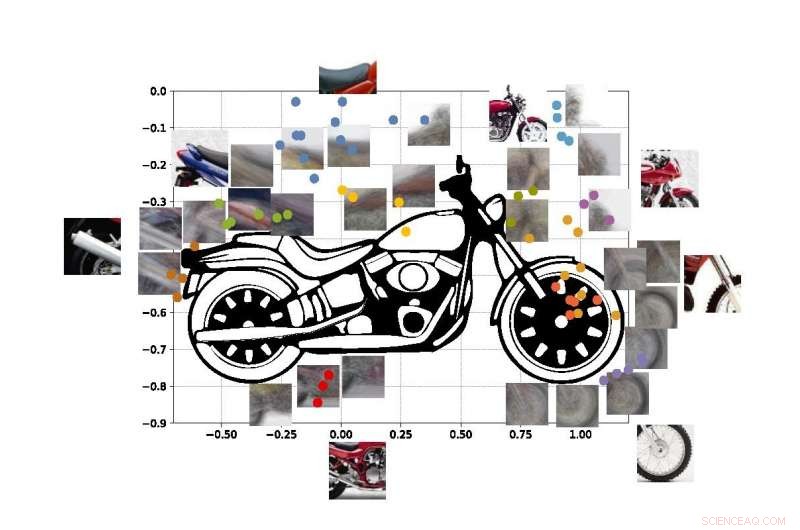
De färgade prickarna i figuren visar uppskattade koordinater för mitten av några av utsikterna i vår motorcykel-SUVM. Varje vyrepresentation är en sammansättning av exempelvyer/lappar som har liknande utseende. Kredit:Lichao Chen, Tianyi Wang, och Vwani Roychowdhury (University of California, Los Angeles).
Forskarna testade systemet med cirka 9, 000 bilder, var och en visar människor och andra föremål. Plattformen kunde bygga en detaljerad modell av människokroppen utan extern vägledning och utan att bilderna var märkta.
Ingenjörerna körde liknande tester med bilder av motorcyklar, bilar och flygplan. I samtliga fall, deras system presterade bättre eller minst lika bra som traditionella datorseendesystem som har utvecklats med många års träning.
Studiens co-senior författare är Thomas Kailath, en professor emeritus i elektroteknik vid Stanford som var Roychowdhurys doktorandrådgivare på 1980-talet. Andra författare är tidigare UCLA-doktorander Lichao Chen (numera forskningsingenjör på Google) och Sudhir Singh (som grundade ett företag som bygger robotiska undervisningskamrater för barn).
Singh, Roychowdhury och Kailath arbetade tidigare tillsammans för att utveckla en av de första automatiska visuella sökmotorerna för mode, den nu slutna StileEye, vilket gav upphov till några av grundtankarna bakom den nya forskningen.