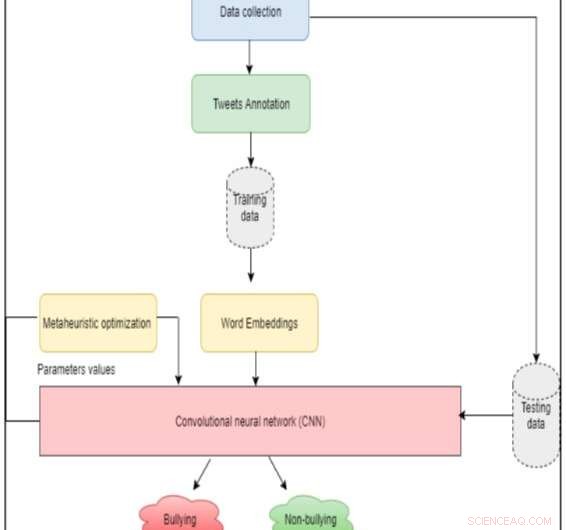
Systemets arkitektur. Kredit:Al-Ajlan &Ykhlef.
Forskare vid King Saud University, i Saudiarabien, har utvecklat en ny metod för att upptäcka nätmobbning på Twitter med hjälp av djupinlärning som kallas OCDD. I motsats till andra metoder för djupinlärning, som extraherar funktioner från tweets och matar dem till en klassificerare, deras metod representerar en tweet som en uppsättning ordvektorer.
På senare år har nätmobbning på sociala medier har blivit en stor och mycket diskuterad fråga. Cybermobbning innebär användning av onlinekommunikationskanaler för att mobba andra användare genom att skicka skrämmande, hotfulla eller kränkande meddelanden. Detta kan få psykiska och ibland livshotande konsekvenser för offren.
Forskare över hela världen har försökt utveckla nya sätt att upptäcka nätmobbning, hantera det och minska dess förekomst på sociala medier. Många metoder för djupinlärning för att identifiera nätmobbning fungerar genom att analysera text- och användaregenskaper. Dock, dessa tekniker har flera begränsningar, vilket kan minska deras prestanda avsevärt.
Till exempel, några av dessa metoder försöker förbättra upptäckten genom att introducera nya funktioner. Ändå kan en ökning av antalet funktioner komplicera faserna för utvinning och urval av funktioner. Dessutom, dessa metoder anser inte att vissa användardata, som ålder och födelsedatum, kan enkelt tillverkas. För att ta itu med begränsningarna hos befintliga metoder för upptäckt av nätmobbning, Monirah A. Al-Ajlan och Mourad Ykhlef, två forskare vid King Saud University, föreslog ett nytt tillvägagångssätt som kallas optimerad Twitter cyberbullying detection (OCDD).
"Till skillnad från tidigare arbete inom detta område, OCDD extraherar inte funktioner från tweets och matar dem till en klassificerare:snarare, den representerar en tweet som en uppsättning ordvektorer, " förklarar forskarna i sin uppsats, publicerades på IEEE Explore och presenterades den 21 st Saudi Computer Society National Computer Conference (NCC). "På det här sättet, ordens semantik bevaras, och funktionsextraktions- och urvalsfaserna kan elimineras."
Al-Ajlan och Ykhlef byggde sitt tillvägagångssätt på märkt träningsdata och genererade ordinbäddningar för enskilda ord med GloVe, en oövervakad inlärningsalgoritm som kan erhålla vektorrepresentationer för ord. Dessa ordinbäddningar matas sedan till ett konvolutionellt neuralt nätverk (CNN) för att upptäcka om de kan associeras med cybermobbning.
CNN-algoritmer består vanligtvis av ett ingångs- och utmatningsskikt, samt flera andra lager. Att manuellt ställa in parametrar för vart och ett av dessa lager kan vara en tidskrävande och utmanande uppgift. Forskarna bestämde sig därför för att införliva en metaheuristisk optimeringsalgoritm i sin modell, som kan underlätta denna process genom att identifiera optimala eller nära optimala värden som ska användas för klassificering.
"OCDD främjar det nuvarande tillståndet för upptäckt av nätmobbning genom att eliminera den svåra uppgiften att extrahera/val av funktioner och ersätta den med ordvektorer som fångar ordens semantik och CNN som klassificerar tweets på ett mer intelligent sätt än traditionella klassificeringsalgoritmer, " skriver forskarna i sin uppsats.
När den testades på textutvinningsuppgifter, OCDD uppnådde mycket lovande resultat. Dock, det ska ännu implementeras och utvärderas i samband med upptäckt av nätmobbning. Forskarna planerar nu att anpassa sitt tillvägagångssätt så att det även kan analysera text på arabiska.
© 2019 Science X Network