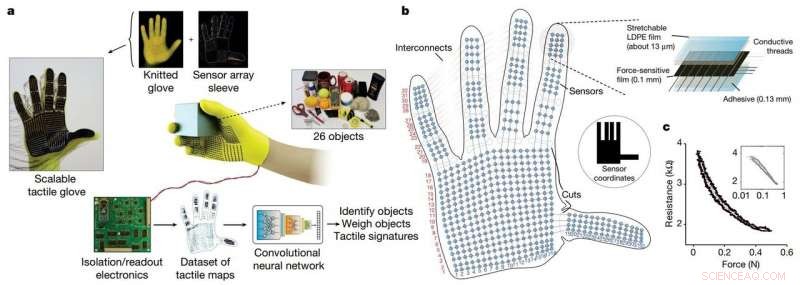
MIT-forskare har utvecklat en låg kostnad, sensorpackad handske som fångar trycksignaler när människor interagerar med föremål. Handsken kan användas för att skapa högupplösta taktila datauppsättningar som robotar kan utnyttja för att bättre identifiera, väga, och manipulera föremål. Kredit:Massachusetts Institute of Technology
Bär en sensorpackad handske när du hanterar en mängd olika föremål, MIT-forskare har sammanställt en enorm datauppsättning som gör det möjligt för ett AI-system att känna igen objekt enbart genom beröring. Informationen kan utnyttjas för att hjälpa robotar att identifiera och manipulera objekt, och kan hjälpa till med protesdesign.
Forskarna utvecklade en billig stickad handske, kallad "skalbar taktil handske" (STAG), utrustad med cirka 550 små sensorer över nästan hela handen. Varje sensor fångar upp trycksignaler när människor interagerar med föremål på olika sätt. Ett neuralt nätverk bearbetar signalerna för att "lära sig" en datauppsättning av trycksignalmönster relaterade till specifika objekt. Sedan, systemet använder den datamängden för att klassificera objekten och förutsäga deras vikter genom att känna sig ensamma, utan att någon visuell inmatning behövs.
I en tidning publicerad i Natur , forskarna beskriver en datauppsättning som de sammanställt med STAG för 26 vanliga objekt – inklusive en läskburk, sax, tennis boll, sked, penna, och mugg. Med hjälp av datamängden, systemet förutspådde objektens identiteter med upp till 76 procents noggrannhet. Systemet kan också förutsäga den korrekta vikten för de flesta föremål inom cirka 60 gram.
Liknande sensorbaserade handskar som används idag kostar tusentals dollar och innehåller ofta bara ett 50-tal sensorer som fångar mindre information. Även om STAG producerar mycket högupplöst data, den är gjord av kommersiellt tillgängliga material för totalt cirka $10.
Det taktila avkänningssystemet skulle kunna användas i kombination med traditionell datorseende och bildbaserade datauppsättningar för att ge robotar en mer människoliknande förståelse för att interagera med objekt.
"Människor kan identifiera och hantera föremål bra eftersom vi har taktil feedback. När vi rör vid föremål, vi känner runt och inser vad de är. Robotar har inte så rik feedback, " säger Subramanian Sundaram Ph.D. '18, en tidigare doktorand i datavetenskap och artificiell intelligens Laboratory (CSAIL). "Vi har alltid velat att robotar ska göra vad människor kan göra, som att diska eller andra sysslor. Om du vill att robotar ska göra dessa saker, de måste kunna manipulera föremål riktigt bra."
Forskarna använde också datasetet för att mäta samarbetet mellan handens regioner under objektinteraktioner. Till exempel, när någon använder mellanleden på sitt pekfinger, de använder sällan tummen. Men spetsarna på pek- och långfingret motsvarar alltid tummen. "Vi visar kvantifierbart, för första gången, den där, om jag använder en del av min hand, hur sannolikt är det att jag använder en annan del av min hand, " han säger.
Protestillverkare kan potentiellt använda information för att, säga, välj optimala platser för att placera trycksensorer och hjälp till att anpassa proteserna till de uppgifter och föremål som människor regelbundet interagerar med.
Med Sundaram på tidningen är:CSAIL postdocs Petr Kellnhofer och Jun-Yan Zhu; CSAIL doktorand Yunzhu Li; Antonio Torralba, en professor i EECS och chef för MIT-IBM Watson AI Lab; och Wojciech Matusik, en docent i elektroteknik och datavetenskap och chef för gruppen Computational Fabrication.
STAG som en plattform för att lära av det mänskliga greppet. Kreditera: Natur (2019). DOI:10.1038/s41586-019-1234-z
STAG är laminerad med en elektriskt ledande polymer som ändrar motståndet mot applicerat tryck. Forskarna sydde ledande trådar genom hål i den ledande polymerfilmen, från fingertopparna till handflatans bas. Gängorna överlappar varandra på ett sätt som gör dem till trycksensorer. När någon som bär handsken känner, hissar, håller, och tappar ett föremål, sensorerna registrerar trycket vid varje punkt.
Trådarna ansluter från handsken till en extern krets som översätter tryckdata till "taktila kartor, " som i huvudsak är korta videor av prickar som växer och krymper över en grafik av en hand. Prickarna representerar platsen för tryckpunkter, och deras storlek representerar kraften – ju större prick, desto större tryck.
Från dessa kartor, forskarna sammanställde en datauppsättning på cirka 135, 000 videorutor från interaktioner med 26 objekt. Dessa ramar kan användas av ett neuralt nätverk för att förutsäga objektens identitet och vikt, och ge insikter om det mänskliga greppet.
För att identifiera föremål, forskarna designade ett konvolutionellt neuralt nätverk (CNN), som vanligtvis används för att klassificera bilder, att associera specifika tryckmönster med specifika föremål. Men tricket var att välja ramar från olika typer av grepp för att få en helhetsbild av föremålet.
Tanken var att efterlikna hur människor kan hålla ett föremål på några olika sätt för att känna igen det, utan att använda sin syn. Liknande, forskarnas CNN väljer upp till åtta halvslumpmässiga bildrutor från videon som representerar de mest olika greppen – säg, håller en mugg från botten, topp, och hantera.
Men CNN kan inte bara välja slumpmässiga bildrutor från tusentals i varje video, eller så kommer den förmodligen inte att välja distinkta grepp. Istället, den grupperar liknande ramar, vilket resulterar i distinkta kluster som motsvarar unika grepp. Sedan, den drar en ram från vart och ett av dessa kluster, se till att den har ett representativt urval. Sedan använder CNN kontaktmönstren den lärde sig under träningen för att förutsäga en objektklassificering från de valda ramarna.
"Vi vill maximera variationen mellan ramarna för att ge bästa möjliga input till vårt nätverk, " Kellnhofer säger. "Alla ramar inuti ett enda kluster bör ha en liknande signatur som representerar liknande sätt att greppa objektet. Sampling från flera kluster simulerar en människa som interaktivt försöker hitta olika grepp samtidigt som den utforskar ett objekt."
För viktuppskattning, forskarna byggde en separat datauppsättning med cirka 11, 600 bildrutor från taktila kartor över föremål som plockas upp med finger och tumme, höll, och tappade. I synnerhet, CNN var inte utbildad på några ramar det testades på, vilket betyder att det inte kunde lära sig att bara associera vikt med ett föremål. Vid testning, en enda bildruta matades in i CNN. Väsentligen, CNN plockar ut trycket runt handen som orsakas av föremålets vikt, och ignorerar tryck som orsakas av andra faktorer, såsom handpositionering för att förhindra att föremålet glider. Sedan beräknar den vikten baserat på lämpliga tryck.
Systemet skulle kunna kombineras med sensorer som redan finns på robotleder som mäter vridmoment och kraft för att hjälpa dem att bättre förutsäga föremålets vikt. "Foder är viktiga för att förutsäga vikt, men det finns också viktiga viktkomponenter från fingertopparna och handflatan som vi fångar, " säger Sundaram.
Den här historien återpubliceras med tillstånd av MIT News (web.mit.edu/newsoffice/), en populär webbplats som täcker nyheter om MIT-forskning, innovation och undervisning.