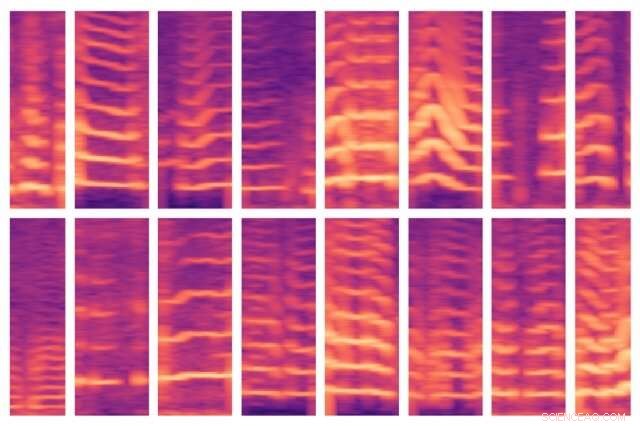
En ny MIT-utvecklad modell automatiserar ett kritiskt steg i att använda AI för medicinskt beslutsfattande, där experter vanligtvis identifierar viktiga funktioner i massiva patientdatauppsättningar för hand. Modellen kunde automatiskt identifiera röstmönster för personer med stämbandsknutor (visas här) och, i tur och ordning, använda dessa funktioner för att förutsäga vilka personer som har och inte har störningen. Kredit:Massachusetts Institute of Technology
MIT-datavetenskapare hoppas kunna påskynda användningen av artificiell intelligens för att förbättra medicinskt beslutsfattande, genom att automatisera ett nyckelsteg som vanligtvis görs för hand – och det blir mer mödosamt när vissa datauppsättningar blir allt större.
Området för prediktiv analys har ett ökande löfte för att hjälpa kliniker att diagnostisera och behandla patienter. Maskininlärningsmodeller kan tränas för att hitta mönster i patientdata för att underlätta sepsisvård, utforma säkrare kemoterapiregimer, och förutsäga en patients risk att få bröstcancer eller att dö på intensiven, för att bara nämna några exempel.
Vanligtvis, träningsdatauppsättningar består av många sjuka och friska försökspersoner, men med relativt lite data för varje ämne. Experter måste sedan hitta just de aspekter - eller "funktioner" - i datamängderna som kommer att vara viktiga för att göra förutsägelser.
Denna "funktionsteknik" kan vara en mödosam och dyr process. Men det blir ännu mer utmanande med ökningen av bärbara sensorer, eftersom forskare lättare kan övervaka patienternas biometri under långa perioder, spåra sömnmönster, gång, och röstaktivitet, till exempel. Efter bara en veckas övervakning, experter kan ha flera miljarder dataprover för varje ämne.
I ett papper som presenterades på Machine Learning for Healthcare-konferensen denna vecka, MIT -forskare visar en modell som automatiskt lär sig funktioner som förutsäger stämbandsstörningar. Funktionerna kommer från en datauppsättning med cirka 100 ämnen, var och en med ungefär en veckas röstövervakningsdata och flera miljarder prover – med andra ord, ett litet antal ämnen och en stor mängd data per ämne. Datauppsättningen innehåller signaler som fångats från en liten accelerometersensor monterad på försökspersoners halsar.
I experiment, modellen använde funktioner som automatiskt extraherades från dessa data för att klassificera, med hög noggrannhet, patienter med och utan stämbandsknölar. Dessa är lesioner som utvecklas i struphuvudet, ofta på grund av mönster av missbruk av rösten, som att ta bort låtar eller skrika. Viktigt, modellen klarade denna uppgift utan en stor uppsättning handmärkta data.
"Det blir allt lättare att samla in långa tidsseriedatauppsättningar. Men du har läkare som behöver tillämpa sin kunskap för att märka datamängden, " säger huvudförfattaren Jose Javier Gonzalez Ortiz, en doktorsexamen student vid MIT Computer Science and Artificial Intelligence Laboratory (CSAIL). "Vi vill ta bort den manuella delen för experterna och överföra all funktionsteknik till en maskininlärningsmodell."
Modellen kan anpassas för att lära sig mönster för alla sjukdomar eller tillstånd. Men förmågan att upptäcka de dagliga röstanvändningsmönstren förknippade med stämbandsknölar är ett viktigt steg för att utveckla förbättrade metoder för att förhindra, diagnostisera, och behandla sjukdomen, säger forskarna. Det kan inkludera att utforma nya sätt att identifiera och uppmärksamma människor på potentiellt skadliga röstbeteenden.
Med Gonzalez Ortiz på tidningen är John Guttag, Dugald C. Jackson professor i datavetenskap och elektroteknik och chef för CSAILs Data Driven Inference Group; Robert Hillman, Jarrad Van Stan, och Daryush Mehta, hela Massachusetts General Hospitals Center for Laryngeal Surgery and Voice Rehabilitation; och Marzyeh Ghassemi, en biträdande professor i datavetenskap och medicin vid University of Toronto.
Tvingad inlärning av funktioner
I åratal, MIT-forskarna har arbetat med Center for Laryngeal Surgery and Voice Rehabilitation för att utveckla och analysera data från en sensor för att spåra patientens röstanvändning under alla vakna timmar. Sensorn är en accelerometer med en nod som fastnar i nacken och är ansluten till en smartphone. När personen pratar, smarttelefonen samlar in data från förskjutningarna i accelerometern.
I sitt arbete, forskarna samlade in en veckas värde av dessa data – kallade "tidsseriedata" – från 104 försökspersoner, varav hälften fick diagnosen stämbandsknölar. För varje patient, det fanns också en matchningskontroll, betyder en frisk person i liknande ålder, sex, ockupation, och andra faktorer.
Traditionellt, experter skulle behöva manuellt identifiera funktioner som kan vara användbara för en modell för att upptäcka olika sjukdomar eller tillstånd. Det hjälper till att förhindra ett vanligt maskininlärningsproblem inom hälso- och sjukvården:överanpassning. Det är när, i träning, en modell "minner" ämnesdata istället för att bara lära sig de kliniskt relevanta egenskaperna. Vid testning, dessa modeller misslyckas ofta med att urskilja liknande mönster i tidigare osynliga ämnen.
"Istället för att lära sig funktioner som är kliniskt signifikanta, en modell ser mönster och säger:"Det här är Sarah, och jag vet att Sarah är frisk, och det här är Peter, som har en stämbandsknöl." Så, det är bara att memorera mönster av ämnen. Sedan, när den ser data från Andrew, som har ett nytt röstanvändningsmönster, den kan inte ta reda på om dessa mönster matchar en klassificering, " säger Gonzalez Ortiz.
Den största utmaningen, sedan, förhindrade övermontering samtidigt som manuell funktionsteknik automatiserades. För detta ändamål, forskarna tvingade modellen att lära sig funktioner utan ämnesinformation. För sin uppgift, det innebar att fånga alla ögonblick när motiv talar och intensiteten i deras röster.
När deras modell kryper igenom ett ämnes data, den är programmerad för att lokalisera röstsegment, som bara utgör cirka 10 procent av uppgifterna. För vart och ett av dessa röstfönster, modellen beräknar ett spektrogram, en visuell representation av spektrumet av frekvenser som varierar över tiden, som ofta används för talbehandlingsuppgifter. Spektrogrammen lagras sedan som stora matriser med tusentals värden.
Men de matriserna är enorma och svåra att bearbeta. Så, en autoencoder – ett neuralt nätverk optimerat för att generera effektiva datakodningar från stora mängder data – komprimerar först spektrogrammet till en kodning med 30 värden. Den dekomprimerar sedan den kodningen till ett separat spektrogram.
I grund och botten, modellen måste säkerställa att det dekomprimerade spektrogrammet liknar den ursprungliga spektrograminmatningen. Genom att göra så, det tvingas lära sig den komprimerade representationen för varje spektrogramsegmentinmatning över varje ämnes hela tidsseriedata. De komprimerade representationerna är funktionerna som hjälper till att träna maskininlärningsmodeller för att göra förutsägelser.
Kartläggning av normala och onormala funktioner
I träning, modellen lär sig att kartlägga dessa funktioner till "patienter" eller "kontroller". Patienter kommer att ha fler röstmönster än kontroller. Vid testning på tidigare osynliga ämnen, modellen kondenserar på liknande sätt alla spektrogramsegment till en reducerad uppsättning funktioner. Sedan, det är majoritetsregler:Om ämnet har mestadels onormala röstsegment, de klassificeras som patienter; om de har mestadels normala, de klassificeras som kontroller.
I experiment, modellen presterade lika exakt som toppmoderna modeller som kräver manuell funktionsteknik. Viktigt, forskarnas modell utfördes exakt i både utbildning och testning, indikerar att det lär sig kliniskt relevanta mönster från data, inte ämnesspecifik information.
Nästa, forskarna vill övervaka hur olika behandlingar – som kirurgi och röstterapi – påverkar röstbeteendet. Om patienternas beteende över tid övergår från onormalt till normalt, de kommer med största sannolikhet att förbättras. De hoppas också kunna använda en liknande teknik på elektrokardiogramdata, som används för att spåra hjärtats muskelfunktioner.
Den här historien återpubliceras med tillstånd av MIT News (web.mit.edu/newsoffice/), en populär webbplats som täcker nyheter om MIT-forskning, innovation och undervisning.