Upphovsman:Bıyık et al.
Under de senaste åren har forskare har försökt utveckla metoder som gör det möjligt för robotar att lära sig nya färdigheter. Ett alternativ är att en robot lär sig dessa nya färdigheter från människor, ställa frågor när det är osäkert om hur man ska bete sig, och lära av den mänskliga användarens svar.
Ett forskargrupp vid Stanford University utvecklade nyligen ett användarvänligt tillvägagångssätt för aktivt belöningsinlärning som kan användas för att träna robotar genom att låta mänskliga användare svara på deras frågor. Detta nya tillvägagångssätt, presenterad i ett papper förpublicerat på arXiv, tränar robotar att ställa frågor som är enkla för en mänsklig användare att svara på och som inte är överflödiga eller onödiga.
"Vår grupp är intresserad av hur robotar kan lära sig vad människor vill, "sa forskarna till TechXplore via e -post." Ett intuitivt sätt att lära sig är genom att ställa frågor. Till exempel, vill du hellre att en autonom bil kör försiktigt eller aggressivt? Ska den här autonoma bilen gå samman framför eller bakom en mänsklig bil? "
Huvudantagandet bakom den senaste studien är att idealiskt robotar bör ställa informativa frågor som får så mycket information som möjligt från mänskliga användare. Med andra ord, en robot ska kunna förstå vad en människa behöver eller vill att de ska göra genom att ställa så få frågor som möjligt.
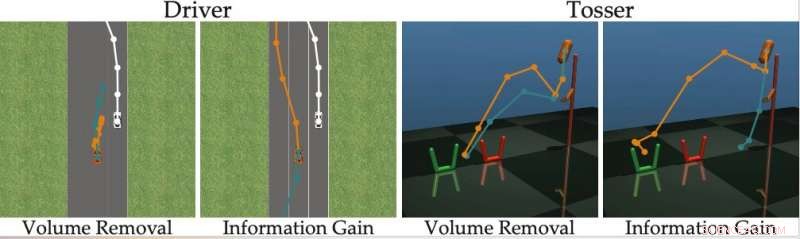
I verkligheten, dock, de flesta befintliga utbildningsmetoder baserade på frågesvar överväger inte hur lätt det kommer att vara för mänskliga användare att svara på specifika frågor formulerade av roboten. Detta resulterar ofta i att användare slösar bort sin tid på att besvara massor av onödiga frågor eller inte kan svara med säkerhet.
"Vi fann att de flesta toppmoderna algoritmer visar de mänskliga alternativen som är (nästan) oskiljbara, hindrar personen från att korrekt svara på robotens frågor, "sa forskarna." För att återgå till vårt exempel, dessa tillvägagångssätt kan fråga:"Vill du hellre slå ihop framför den mänskliga bilen med en hastighet av 29 mph, eller en hastighet på 31 mph? "Detta kan vara informativt för roboten att avgöra om människan vill gå snabbare än 30 mph eller inte, men alternativen är så nära att människor inte kan på ett tillförlitligt sätt svara. "
För att övervinna begränsningarna för befintliga aktiva inlärningsmetoder, forskarna utvecklade en algoritm som kan välja mer effektiva frågor att ställa mänskliga användare. Algoritmen identifierar frågor som mest minskar robotens osäkerhet om en mänsklig användares preferenser (dvs. som maximerar informationsvinsten), samtidigt som man överväger hur lätt det kommer att vara för en mänsklig användare att svara på dem.

Upphovsman:Bıyık et al.
"Inspirerad av bristerna i tidigare arbeten, när vi utvecklade denna algoritm, vi fokuserade på att redogöra för människans förmåga att faktiskt svara på de frågor som roboten ställer, "sa forskarna." Detta är baserat på tanken att endast robotar som svarar för människans förmåga att svara kan exakt och effektivt lära sig vad människor vill. "
Forskarna beräknade informationsvinsten genom att mäta minskningen av entropi (dvs. ett mått på osäkerhet) över den mänskliga användarens preferenser som en funktion av frågan från roboten. Med andra ord, en fråga som maximerar informationsvinsten minskar mest robotens osäkerhet om vad den mänskliga användarens preferenser är. Detta ger robotar ett formellt mål som de kan använda för att välja frågor som är mest informativa.
"En trevlig egenskap hos informationsvinst är att den i sig maximerar robotens osäkerhet (så att roboten lär sig mycket av frågan) samtidigt som den minimerar människans osäkerhet (så att frågan är lätt för människan att svara på), "förklarade forskarna." Att generera frågorna med hjälp av informationsvinster förbättrar således aktivt lärande, inte bara för att frågorna är maximalt informativa, men också för att människan ger färre felaktiga svar. "
Det tillvägagångssätt som forskarna utarbetat väljer girigt den frågan som maximerar informationsvinsten vid varje steg. Väsentligen, roboten upprätthåller en tro (dvs. en sannolikhetsfördelning) över användarens preferenser som den interagerar med och prov från både denna tro och utrymmet för möjliga frågor.
I sista hand, roboten väljer frågan som ger mest informationsvinst över den nuvarande fördelningen av möjliga mänskliga preferenser. Senare, den uppdaterar sin övertygelse om vad användaren vill ha baserat på svaret den får. Denna process upprepas kontinuerligt, låta roboten gradvis förbättra sin prestanda genom att lära sig om användarens preferenser.
"Vi formulerade en beräkningsmässigt bearbetbar metod som gör att vi snabbt kan upptäcka mänskliga preferenser för riktiga robotuppgifter, överträffar tidigare metoder, "sa forskarna." I vår studie, användare föredrog vår metod framför andra toppmoderna tekniker. "
I deras studie, det Stanford-baserade teamet visade att träning av en robot för att ställa frågor som maximerar informationsvinsten har samma beräkningskomplexitet som toppmoderna metoder. Med andra ord, det är inte svårare för roboten att hitta dessa informativa frågor, jämfört med dem som genereras av andra tillvägagångssätt.
"Vi påpekar också att vårt tillvägagångssätt har flera önskvärda matematiska egenskaper, som submodularitet, vilket gör att vi kan ta de förlängningar och teoretiska gränser som utvecklats för tidigare tillvägagångssätt och även använda dem med vår metod, "sa forskarna." Till exempel, vi kan använda tidigare arbeten för att hitta flera informativa frågor samtidigt, istället för att söka efter en fråga i taget. "
Teamet utvärderade sitt aktiva belöningsinlärningssätt i en serie simuleringar och fann att det tillåter robotar att förstå mänskliga preferenser snabbare och mer exakt än andra toppmoderna metoder. Detta befanns också vara sant i situationer där människor kan svara på svåra frågor korrekt eller när deras svar är "Jag vet inte".
Forskarna genomförde också en användarstudie där de bad mänskliga deltagare att svara på frågor som genereras av deras metod och andra som genererats med hjälp av andra toppmoderna metoder. Feedbacken de samlade tyder på att människor tycker att frågor som genereras av deras tillvägagångssätt är mycket lättare att svara på. Dessutom, users often felt that robots using the new method had acquired a more accurate representation of their preferences than they did with previously proposed approaches.
"Considering all of our contributions together, we took a step toward enabling robots to determine human preferences, " the researchers said. "We showed that the true objective that we originally wanted the robot to maximize—-asking questions to gain as much information as possible—-can actually be solved with the same computational complexity as existing methods."
I framtiden, the active reward-learning technique developed by this team of researchers could help to train robots more effectively, making them more attuned to user preferences. Dessutom, it could be used to teach robots to ask questions that humans can easily understand and answer. In their future studies, the researchers would also like to investigate methods for training robots to give useful explanations for their actions.
"We are excited about robots that not only ask good questions, but can also explain why they are asking those questions, " the researchers said. "We imagine a scenario where a self-driving car visualizes two different merging options for the human, and then clarifies that it is asking about these options because it is rush hour, and it wants to determine whether it should behave more or less aggressively."
© 2019 Science X Network














