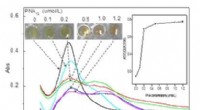
Kredit:Matti Ahlgren, Aalto-universitetet
Om vårdgivare exakt kunde förutsäga hur deras tjänster skulle användas, de skulle kunna spara stora summor pengar genom att inte behöva allokera medel i onödan. Deep learning artificiell intelligensmodeller kan vara bra på att förutsäga framtiden givet tidigare beteende, och forskare baserade i Finland har utvecklat en som kan förutsäga när och varför äldre kommer att använda sjukvården.
Forskare vid Finlands centrum för artificiell intelligens (FCAI), Aalto-universitetet, Helsingfors universitet, och Finlands institut för hälsa och välfärd (THL) utvecklade en så kallad riskanpassningsmodell för att förutsäga hur ofta äldre personer söker vård på en vårdcentral eller sjukhus. Resultaten tyder på att den nya modellen är mer exakt än traditionella regressionsmodeller som vanligtvis används för denna uppgift, och kan tillförlitligt förutsäga hur situationen förändras under åren.
Riskjusteringsmodeller använder sig av data från tidigare år, och används för att fördela sjukvårdsmedel på ett rättvist och effektivt sätt. Dessa modeller används redan i länder som Tyskland, Nederländerna, och USA. Dock, detta är det första beviset på att djupa neurala nätverk har potential att avsevärt förbättra noggrannheten hos sådana modeller.
"Utan en riskjusteringsmodell, vårdgivare vars patienter är sjuka oftare än genomsnittet skulle behandlas orättvist, "Pekka Martinen, Biträdande professor vid Aalto-universitetet och FCAI säger. Äldre är ett bra exempel på en sådan patientgrupp. Målet med modellen är att ta hänsyn till dessa skillnader mellan patientgrupper vid finansieringsbeslut.
Enligt Yogesh Kumar, huvudförfattaren till forskningsartikeln och doktorand vid Aalto-universitetet och FCAI, resultaten visar att djupinlärning kan hjälpa till att utforma mer exakta och tillförlitliga riskjusteringsmodeller. "Att ha en korrekt modell har potential att spara flera miljoner dollar, " påpekar Kumar.
Forskarna tränade modellen genom att använda data från THL:s register över primärvårdsbesök. Uppgifterna består av öppenvårdsinformation för varje finsk medborgare som är 65 år eller äldre. Uppgifterna har pseudonymiserats, vilket innebär att enskilda personer inte kan identifieras. Detta var första gången forskare använde denna databas för att träna en modell för djup maskininlärning.
Resultaten visar att träning av en djup modell inte nödvändigtvis kräver en enorm datauppsättning för att ge tillförlitliga resultat. Istället, den nya modellen fungerade bättre än enklare, räkningsbaserade modeller även när den använde endast en tiondel av all tillgänglig data. Med andra ord, det ger exakta förutsägelser även med en relativt liten datauppsättning, vilket är ett anmärkningsvärt fynd, eftersom det alltid är svårt att skaffa stora mängder medicinsk data.
"Vårt mål är inte att omsätta modellen som utvecklats i den här forskningen i praktiken som sådan utan att integrera funktioner i modeller för djupinlärning med befintliga modeller, kombinera de bästa sidorna av båda. I framtiden, Målet är att använda dessa modeller för att stödja beslutsfattande och fördela medel på ett mer rimligt sätt, " förklarar Marttinen.
Implikationerna av denna forskning är inte begränsade till att förutsäga hur ofta äldre människor besöker en vårdcentral eller sjukhus. Istället, enligt Kumar, forskarnas arbete kan enkelt utökas på många sätt, till exempel, genom att enbart fokusera på patientgrupper som diagnostiserats med sjukdomar som kräver mycket dyra behandlingar eller vårdcentraler på specifika platser över hela landet.
Forskningsresultaten publicerades i den vetenskapliga publikationsserien av Proceedings of Machine Learning Research .