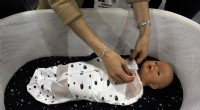
Exempelstillbilder av modellgenererade översättningar (översta raden är verkliga mänskliga bilder, nedersta raden är falska robotbilder). Kredit:Smith et al.
På senare år har forskarlag över hela världen har använt förstärkningsinlärning (RL) för att lära robotar hur man utför en mängd olika uppgifter. Att träna dessa algoritmer, dock, kan vara mycket utmanande, eftersom det också kräver betydande mänskliga ansträngningar för att korrekt definiera de uppgifter som roboten ska utföra.
Ett sätt att lära robotar hur man utför specifika uppgifter är genom demonstrationer av människor. Även om detta kan verka enkelt, det kan vara mycket svårt att genomföra, främst för att robotar och människor har väldigt olika kroppar, sålunda är de kapabla till olika rörelser.
Forskare vid University of California Berkeley har nyligen utvecklat ett nytt ramverk som kan hjälpa till att övervinna några av de utmaningar man stöter på när man tränar robotar via imitationsinlärning (dvs. med hjälp av mänskliga demonstrationer). Deras ramar, kallas AVID, i baserad på två djupinlärningsmodeller utvecklade i tidigare forskning.
"När man utvecklar AVID, vi byggde till stor del på två nya verk, CycleGAN och SOLAR, som introducerade tillvägagångssätt för att hantera grundläggande begränsningar som har hindrat lärande från mänskliga videor i domänskifte och träning på en fysisk robot från visuell input, respektive, "Laura Smith, en av forskarna som genomförde studien, berättade för TechXplore.
Istället för att använda tekniker som inte tar hänsyn till skillnaderna mellan en robot och en mänsklig användares kropp, Smith och hennes kollegor använde Cycle-GAN, en teknik som kan transformera bilder på pixelnivå. Genom att använda Cycle-GAN, deras metod omvandlar mänskliga demonstrationer av hur man slutför en given uppgift till videor av en robot som slutför samma uppgift. De använde sedan dessa videor för att utveckla en belöningsfunktion för en RL-algoritm.

Exempelstillbilder av modellgenererade översättningar (översta raden är verkliga mänskliga bilder, nedersta raden är falska robotbilder). Kredit:Smith et al.
"AVID fungerar genom att låta roboten observera en människa utföra någon uppgift och sedan föreställa sig hur det skulle se ut för sig själv att utföra samma sak, " förklarade Smith. "För att lära sig hur man faktiskt uppnår denna tänkta framgång, vi låter roboten lära sig genom att trial and error."
Genom att använda ramverket som utvecklats av Smith och hennes kollegor, en robot lär sig uppgifter ett steg i taget, återställa varje steg och försöka igen utan att kräva en mänsklig användares ingripande. Inlärningsprocessen blir därmed till stor del automatiserad, med roboten som lär sig nya färdigheter med minimal mänsklig inblandning.
"En viktig fördel med vårt tillvägagångssätt är att den mänskliga läraren kan interagera med robotstudenten medan den lär sig, " förklarade Smith. "Dessutom, vi utformar vår träningsram för att vara mottaglig för att lära sig långsiktigt beteende med minimal ansträngning."
Forskarna utvärderade deras tillvägagångssätt i en serie försök och fann att det effektivt kan lära robotar hur man utför komplexa uppgifter, som att använda en kaffemaskin, helt enkelt genom att bearbeta 20 minuters råa mänskliga demonstrationsvideor och öva på den nya färdigheten i 180 minuter. Dessutom, AVID överträffade alla andra tekniker som det var, inklusive imitationsablation, pixel-space ablation, och beteendemässiga kloningsmetoder.
"Vad vi fann är att vi kan utnyttja CycleGAN för att effektivt göra videor av mänskliga demonstrationer begripliga för roboten utan att kräva en tråkig datainsamlingsprocess, ", sade Smith. "Vi visar också att utnyttjandet av flerstegskaraktären hos temporärt utökade uppgifter låter oss lära oss robust beteende samtidigt som träningen blir enkel. Vi ser vårt arbete som ett meningsfullt steg mot att få verkliga implementeringar av autonoma robotar inom räckhåll eftersom det ger oss en mycket naturlig, intuitivt sätt för oss att lära dem."
Det nya ramverket för lärande som introducerats av Smith och hennes kollegor möjliggör en annan typ av imitationsinlärning, där en robot lär sig att slutföra ett mål på högre nivå i taget, fokusera på det som den finner mest utmanande i varje steg. Dessutom, istället för att kräva att mänskliga användare återställer scenen efter varje övningsprov, det låter robotar återställa scenen automatiskt och fortsätta att öva. I framtiden, AVID kan förbättra imitationsinlärningsprocesser, gör det möjligt för utvecklare att träna robotar snabbare och mer effektivt.
"En av de viktigaste begränsningarna i vårt arbete hittills är att vi kräver datainsamling och träning av CycleGAN för varje ny scen som roboten kan stöta på. Vi hoppas kunna behandla CycleGAN-träningen som en engångsföreteelse, förskottskostnad, så att träning en gång på en stor mängd data kan göra det möjligt för roboten att mycket snabbt ta till sig en mängd olika färdigheter med några demonstrationer och lite övning."
© 2020 Science X Network