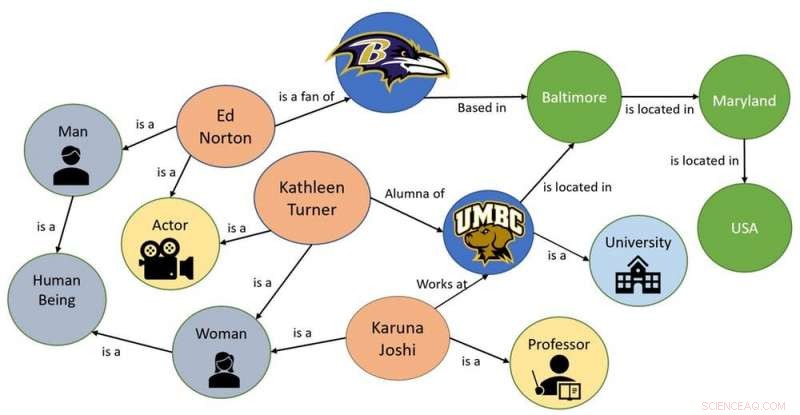
Ett exempel på en enkel kunskapsgraf. Kredit:Karuna Pande Joshi, CC BY-ND
Du är eftersläpande bitar av personlig information – som kreditkortsnummer, shoppingpreferenser och vilka nyhetsartiklar du läser – när du reser runt på internet. Stora internetföretag tjänar pengar på den här typen av personlig information genom att dela den med sina dotterbolag och tredje part. Allmänhetens oro över integritet på nätet har lett till lagar utformade för att styra vem som får dessa uppgifter och hur de kan använda dem.
Kampen pågår. Demokrater i den amerikanska senaten presenterade nyligen ett lagförslag som innehåller straff för teknikföretag som misshandlar användarnas personuppgifter. Den lagen skulle ansluta sig till en lång lista av regler och förordningar över hela världen, inklusive Payment Card Industry Data Security Standard som reglerar kreditkortstransaktioner online, Europeiska unionens allmänna dataskyddsförordning, California Consumer Privacy Act som trädde i kraft i januari, och U.S. Children's Online Privacy Protection Act.
Internetföretag måste följa dessa regler eller riskera dyra stämningar eller statliga sanktioner, såsom Federal Trade Commissions nyligen utdömda böter på 5 miljarder USD på Facebook.
Men det är tekniskt utmanande att i realtid avgöra om en integritetsintrång har inträffat, en fråga som blir ännu mer problematisk när internetdata flyttas till extrem skala. För att se till att deras system följer företag förlitar sig på mänskliga experter för att tolka lagarna – en komplex och tidskrävande uppgift för organisationer som ständigt lanserar och uppdaterar tjänster.
Min forskargrupp vid University of Maryland, Baltimore County, har utvecklat nya teknologier för maskiner för att förstå datasekretesslagar och upprätthålla efterlevnad av dem med hjälp av artificiell intelligens. Dessa tekniker kommer att göra det möjligt för företag att se till att deras tjänster överensstämmer med integritetslagar och även hjälpa regeringar att i realtid identifiera de företag som bryter mot konsumenternas integritetsrättigheter.
Hjälper maskiner att förstå regler
Regeringar genererar integritetsföreskrifter online som vanligt textdokument som är lätta för människor att läsa men svåra för maskiner att tolka. Som ett resultat, Regelverket måste granskas manuellt för att säkerställa att inga regler bryts när en medborgares privata data analyseras eller delas. Detta drabbar företag som nu måste följa en skog av regelverk.
Regler och förordningar är ofta tvetydiga till sin design eftersom samhällen vill ha flexibilitet i att implementera dem. Subjektiva begrepp som bra och dåliga varierar mellan kulturer och över tid, så lagar är utformade i allmänna eller vaga ordalag för att ge utrymme för framtida ändringar. Maskiner kan inte bearbeta denna vaghet – de fungerar i 1:or och 0:or – så de kan inte "förstå" integritet som människor gör. Maskiner behöver specifika instruktioner för att förstå den kunskap som en föreskrift bygger på.

Forskarnas ansökan extraherade automatiskt deontiska regler, såsom tillstånd och skyldigheter, från två integritetsförordningar. Enheter som är involverade i reglerna är markerade med gult. Modala ord som hjälper till att identifiera om en regel är en behörighet, förbud eller skyldighet är markerade i blått. Grå anger den tidsmässiga eller tidsbaserade aspekten av regeln. Kredit:Karuna Pande Joshi, CC BY-ND
Ett sätt att hjälpa maskiner att förstå ett abstrakt koncept är att bygga en ontologi, eller en graf som representerar kunskapen om det begreppet. Lånar begreppen ontologi från filosofin, nya datorspråk, som UGLA, har utvecklats i AI. Dessa språk kan definiera begrepp och kategorier inom ett ämnesområde eller en domän, visa deras egenskaper och visa relationerna mellan dem. Ontologier kallas ibland "kunskapsdiagram, " eftersom de är lagrade i grafliknande strukturer.
När jag och mina kollegor började titta på utmaningen att göra sekretessbestämmelser begripliga för maskiner, vi bestämde att det första steget skulle vara att fånga all nyckelkunskap i dessa lagar och skapa kunskapsgrafer för att lagra den.
Extrahera villkoren och reglerna
Nyckelkunskapen i regelverket består av tre delar.
Först, det finns "konstvillkor":ord eller fraser som har exakta definitioner inom en lag. De hjälper till att identifiera den enhet som förordningen beskriver och tillåter oss att beskriva dess roller och ansvar på ett språk som datorer kan förstå. Till exempel, från EU:s allmänna dataskyddsförordning, vi extraherade konsttermer som "Konsumenter och leverantörer" och "böter och verkställighet."
Nästa, vi identifierade deontiska regler:meningar eller fraser som förser oss med filosofisk modal logik, som handlar om deduktivt beteende. Deontiska (eller moraliska) regler inkluderar meningar som beskriver plikter eller skyldigheter och delas huvudsakligen in i fyra kategorier. "Behörigheter" definierar rättigheterna för en enhet/aktör. "Obligations" definierar ansvaret för en enhet/aktör. "Förbud" är villkor eller handlingar som inte är tillåtna. "Dispenser" är valfria eller icke-obligatoriska uttalanden.
För att förklara detta med ett enkelt exempel, överväga följande:

kunskapsdiagram för GDPR-bestämmelser. Kredit:Karuna Pande Joshi, CC BY-ND
Vissa av dessa regler gäller för alla enhetligt under alla förhållanden; medan andra kan gälla delvis, till endast en enhet eller baserat på villkor som alla kommit överens om.
Liknande regler som beskriver do's and don'ts gäller för personuppgifter online. Det finns tillstånd och förbud för att förhindra dataintrång. Det finns skyldigheter för de företag som lagrar uppgifterna för att säkerställa dess säkerhet. Och det finns dispenser för utsatta demografier som minderåriga.
Min grupp utvecklade tekniker för att automatiskt extrahera dessa regler från regelverket och spara dem i en kunskapsgraf.
För det tredje, vi var också tvungna att ta reda på hur vi skulle inkludera de korshänvisningar som ofta används i juridiska förordningar för att referera till text i ett annat avsnitt av förordningen eller i ett separat dokument. Det är viktiga kunskapselement som också bör lagras i kunskapsgrafen.
Regler på plats, skannar efter överensstämmelse
Efter att ha definierat alla nyckelenheter, egenskaper, relationer, regler och policyer för en datasekretesslag i en kunskapsgraf, mina kollegor och jag kan skapa applikationer som kan resonera om datasekretessreglerna med hjälp av dessa kunskapsdiagram.
Dessa applikationer kan avsevärt minska den tid det kommer att ta företag att avgöra om de följer dataskyddsbestämmelserna. De kan också hjälpa tillsynsmyndigheter att övervaka datarevisionsspår för att avgöra om företag som de övervakar följer reglerna.
Denna teknik kan också hjälpa individer att få en snabb ögonblicksbild av sina rättigheter och skyldigheter med avseende på den privata information de delar med företag. När maskiner snabbt kan tolka länge, komplexa integritetspolicyer, människor kommer att kunna automatisera många vardagliga efterlevnadsaktiviteter som görs manuellt idag. De kanske också kan göra dessa policyer mer begripliga för konsumenterna.
Den här artikeln är återpublicerad från The Conversation under en Creative Commons-licens. Läs originalartikeln.