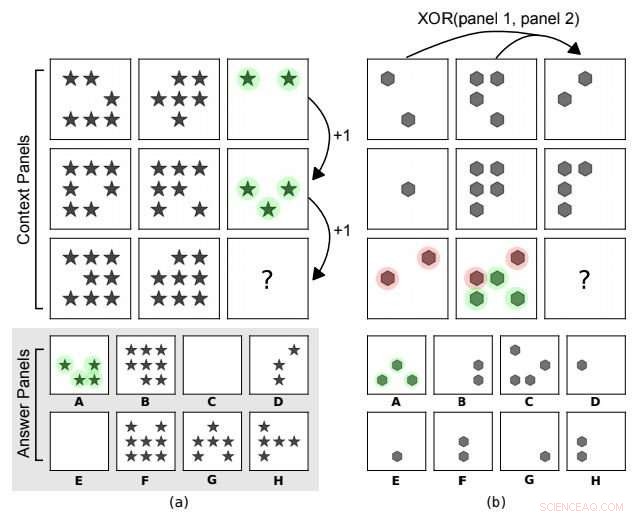
Progressiva matriser i korpstil. I (a) är den underliggande abstrakta regeln en aritmetisk progression av antalet former längs kolumnerna. I (b) finns det en XOR -relation på formpositionerna längs raderna (panel 3 =XOR (panel 1, panel 2)). Andra funktioner som formtyp spelar ingen roll. A är det rätta valet för båda. Upphovsman:arXiv:1807.04225 [cs.LG]
Testning, testning:DeepMind lägger ner AI för ett IQ -test. Även om AI -prestandaresultaten inte är svindlande i trumf eller matchning av mänskligt resonemang, det är en början. AI -forskare inser att det har visat sig svårt att fastställa sin förmåga att resonera kring abstrakta begrepp. DeepMind ville se hur AI kunde prestera och teamet föreslog en datamängd och utmaning att undersöka abstrakta resonemang.
Kan AI matcha våra förmågor för abstrakt resonemang? Kommer djupa neurala nätverk att bättre kunna lösa abstrakta visuella resonemangsproblem i framtiden? DeepMind -forskarna har verkligen varit med om saken.
Deras papper, "Mätning av abstrakta resonemang i neurala nätverk, "finns på arXiv. Författare är David Barrett, Felix Hill, Adam Santoro, Ari Morcos, Timothy Lillicrap, från DeepMind. Du kan kolla vad de letade efter och hur de testade. Tidningen fokuserar i grunden på ett tillvägagångssätt för att mäta abstrakt resonemang i inlärningsmaskiner. I deras diskussion, sa laget, ja, det har gjorts framsteg i resonemang och inlärning av abstrakt representation i neurala nät - men i vilken utsträckning dessa modeller uppvisar något liknande allmänt abstrakt resonemang "är föremål för mycket debatt."
Modellerna för att lyckas var tvungna att klara generaliseringsregimer där utbildnings- och testdata skiljde sig åt. De sa att de presenterade en arkitektur med en struktur för att uppmuntra resonemang. Resultat:Blandad påse. De sa att deras modell var skicklig på vissa former av generalisering, men svag på andra.
Ändå, det är anmärkningsvärt att de undersökte sätt att mäta och framkalla starkare abstrakt resonemang i neurala nätverk.
"Standarda mänskliga IQ-test kräver ofta att testare tolkar uppfattningsvis enkla visuella scener genom att tillämpa principer som de har lärt sig genom vardagliga erfarenheter, "sa en DeepMind -blogg." Vi har ännu inte möjlighet att utsätta maskininlärningsagenter för en liknande ström av "vardagliga upplevelser", vilket betyder att vi inte enkelt kan mäta deras förmåga att överföra kunskap från den verkliga världen till visuella resonemangstester. Ändå, vi kan skapa en experimentell uppsättning som fortfarande använder människors visuella resonemangstester till god användning. "
De fortsatte att bygga en generator för matrisproblem med en uppsättning abstrakta faktorer. Teamet uppmuntrar mer forskning i abstrakt resonemang, och de gjorde sin dataset tillgänglig för allmänheten.
Storbildsfrågan är om forskare kan uppnå mänskliga analytiska resonemang.
Medan deras IQ-testgivande resultat kan ha varit en blandad påse, forskarna ser inte detta som ett spel att vinna eller ge upp. De kommer att fortsätta sitt arbete med att utforska strategier för att förbättra generalisering och utforska framtida modeller. Som CIO Dyk påpekade, "Intelligenta assistenter har matats med massor av data för att hjälpa konsumenter i nästan alla tänkbara områden, men när de uppvisas med okända problem kan det fortfarande komma till kort. "
Författarna skrev, i deras abstrakt, "vi föreslår en dataset och utmaning som är utformad för att undersöka abstrakta resonemang, inspirerad av ett välkänt mänskligt IQ-test. För att lyckas med denna utmaning, modeller måste klara olika generaliseringsregimer där tränings- och testdata skiljer sig på klart definierade sätt. Vi visar att populära modeller som ResNets presterar dåligt, även när tränings- och testuppsättningarna skiljer sig åt endast minimalt, och vi presenterar en ny arkitektur, med en struktur utformad för att uppmuntra resonemang, det går betydligt bättre. "
CIO Dyk beskrev deras tester som visuella IQ -tester. I processen, författarna var intresserade av att se prestanda i förmågor att generalisera när testdata var olika.
Att matcha AI med mänskliga förmågor för abstraktion fortsätter att vara en uppförsbacke.
Som CIO Dyk 's Alex Hickey skrev, AI skulle behöva skilja på olika betydelser mellan att "äta spagetti med ost" och "äta spagetti med hundar".
Tidningen kommenterade att testa kapaciteten hos neurala nät kan vara knepigt och neurala nätverk har sina fallgropar, med tanke på deras förmåga att memorera och förmåga att utnyttja ytliga statistiska signaler.
© 2018 Tech Xplore