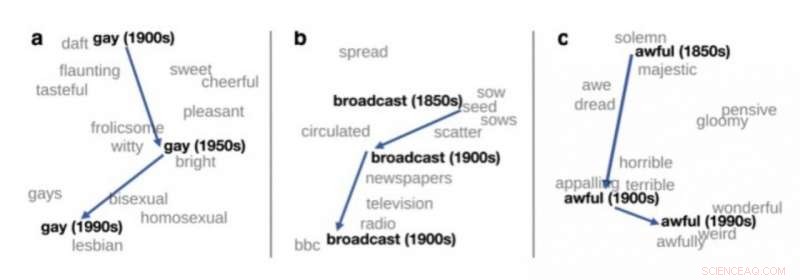
Tvådimensionell syn på förändringen i betydelsen av tre engelska ord, hämtat från Hamilton et al. (2016). Kredit:upf
Distributionssemantik erhåller representationer av ordens betydelse genom att bearbeta tusentals texter och extrahera generaliseringar med hjälp av beräkningsalgoritmer. Trots populariteten för distributionssemantik inom sådana områden som beräkningslingvistik och kognitionsvetenskap, dess inverkan på teoretisk lingvistik har hittills varit mycket begränsad.
Forskning av Gemma Boleda, chef för forskargruppen Computational Linguistics and Language Theory (COLT) och forskningsprofessor i ICREA vid institutionen för översättnings- och språkvetenskaper vid UPF, publiceras i tidskriften Årlig översyn av lingvistik , ger en kritisk genomgång av de rikliga studier som finns tillgängliga om distributionssemantik, med särskild vikt vid de resultat som är relevanta för teoretisk lingvistik. Specifikt finns det tre områden:semantisk förändring, polysemi och komposition, och gränssnittet grammatik-semantik.
Gemma Boledas forskning syftar till att koppla samman teoretiska och beräkningsmässiga tillvägagångssätt för att avancera i den samlade kunskapen om hur språk fungerar. En av metoderna hon har forskat mycket om är distributionssemantik, som gör det möjligt att erhålla representationer av ord automatiskt. Dessa representationer har visat sig återspegla betydande språkliga egenskaper, till exempel hur två ord är lika:en person kommer att berätta att "hund" och "valp" är väldigt lika, och ändå är "hund" och "demokrati" knappast lika; distributionssemantik kommer att säga detsamma, tack vare att det framkallar språkliga egenskaper baserade på texter skrivna av människor. Därför, distributionssemantik ger radikalt empiriska representationer.
Distributionssemantik gör det möjligt att analysera användningen av ord och utvecklingen av deras betydelse
Distributionssemantik ger en attraktiv, kompletterande ramar till andra, mer traditionella metoder, inte bara för att det är radikalt empiriskt utan också för att det ger flerdimensionella representationer:två ord kan liknas på en meningsdimension ("pizza" och "pasta" är typer av mat), eller på en annan ("pizza" och "hjul" är runda). För att representera alla aspekter av mening, flerdimensionella representationer behövs. Distributionssemantik kan fånga de vanliga användningsområdena för två ord, såväl som deras differentierande faktorer.
En av de viktiga tillämpningarna av distributionssemantik i teoretisk lingvistik är upptäckten av betydelseförändringar. Om språkdata från olika perioder behandlas, som böcker på engelska från 1900, 1950 och 1990, distributionssemantik kan användas för att automatiskt upptäcka vissa ords förändring i betydelse. Till exempel, ordet "gay" på engelska i början av förra seklet betydde "glad" och har använts alltmer för att betyda "homosexuell".
Aspekter av forskning om distributionssemantik som bidrar till språkteorin
Från analysen av de studerade verken, Boleda drar slutsatsen att det finns tillräckliga bevis för att de solida resultaten av distributionssemantik ska kunna importeras direkt till forskning inom teoretisk lingvistik.
"Det finns minst fyra aspekter av forskning inom distributionssemantik som kan bidra till språkteorin. Den första aspekten är utforskande:distributionsrepresentationer kan användas för att utforska storskalig data, till exempel genom att undersöka likheten mellan ord. Den andra är som ett verktyg för att identifiera specifika fall av språkliga fenomen. Till exempel, ord kan identifieras vars innebörd har ändrats när man jämför representationerna från texter från olika perioder. Den tredje är som en testbänk:att utvärdera olika språkliga hypoteser i fördelningstermer. Den fjärde och svåraste är upptäckten av nya språkliga fenomen eller relevanta teoretiska trender i data, " förklarar författaren i sitt arbete.