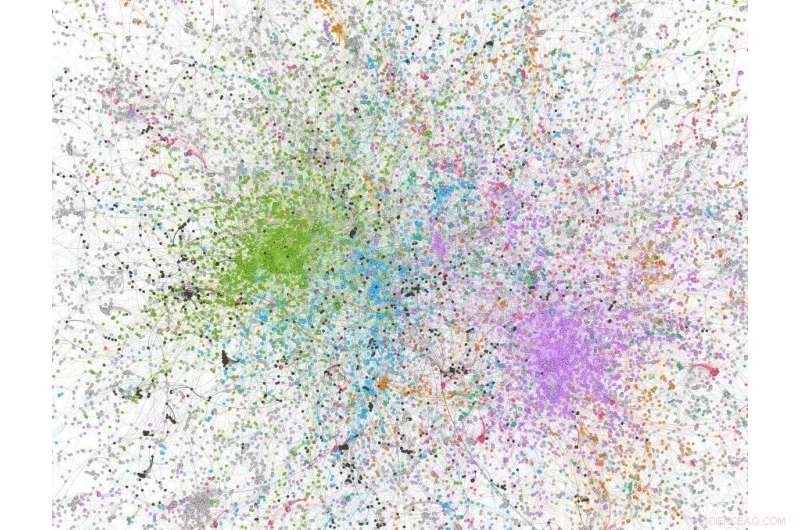
Nätverksanalyssiffra härledd från ett urval av 100, 000 tweets med 'covid' i tweeten; noder färgade i grönt är alt-höger/starkt konservativa Twitter-användare/-organisationer. Kredit:Dhiraj Murthy, UT Austin
Av de otaliga sätt som forskare bekämpar spridningen av coronaviruset, studera Tweets kanske inte är det första som kommer att tänka på. Men nu, som i tidigare kriser, att använda en av världens ledande meddelandetjänster i realtid kan hjälpa till att identifiera nya hotspots för pandemi, lyfta fram nya symtom, eller tolka hur människor och samhällen reagerar på order att öva social distansering.
Texas Advanced Computing Center (TACC) expertteam för datavetenskap har underlättat analys av sociala medier tidigare, och har utvecklat verktyg för maskininlärning för att bättre dra ut nålar av insikt ur Twittervers väldiga höstackar.
Med start i mars, TACC började äta stora mängder tweets dagligen – ungefär 40 miljoner meddelanden, varav en miljon är unika. Genom att kombinera sin samling med liknande insatser från grupper på UT Austin, University of Southern California, och George State University, de har utökat sin samling av covid-19-relaterade tweets tillbaka till januari. (Förra veckan, Twitter meddelade att de kommer att släppa nya API-slutpunkter till sin egen covid-19-relaterade tweetsamling för godkända utvecklare och forskare.)
"Det finns ett stort intresse för den här typen av samlingar. Det är väldigt användbart inom datavetenskap, sa Weijia Xu, som leder gruppen Scalable Computational Intelligence på TACC.
I dag, TACC tillkännagav ett nytt GitHub-förråd där intresserade forskare kan komma åt både pekare till rå Twitter-data relaterad till COVID-19 och storskaliga analyser som underlättas av TACC:s superdatorer.
Den första av de analyser som är tillgängliga för forskare är en uppsättning n-gram:sammanhängande sekvenser av ord från ett givet urval av tweets. Topp 1, 000 en-, två-, och treordssekvenser har satts samman för varje dag av pandemin. Att montera till och med ett enda gram från flera miljoner tweets kan ta upp till en timme på en bärbar dator på grund av mängden databehandling som är involverad, men kan göras på några minuter på TACC:s superdatorer.
TACC-forskargruppen, leds av Xu, har också arbetat med ämnesmodelleringsanalyser, identifiera termer som ofta förekommer i samband med varandra, men inte nödvändigtvis i ordning. Dessa kommer att läggas till i GitHub-förrådet under de kommande veckorna.
Båda metoderna för klustring kan vara till hjälp för att identifiera trender i hur pandemin, och människors svar på det, utvecklas.
Framtida projekt som använder data inkluderar en sökbar offentlig databas; enhetsanalys – inspektera tweets för kända enheter som offentliga personer eller organisationer och returnera information om dessa enheter; och händelsedetektering – upptäcker automatiskt förekomsten av händelser och kategoriserar dem.
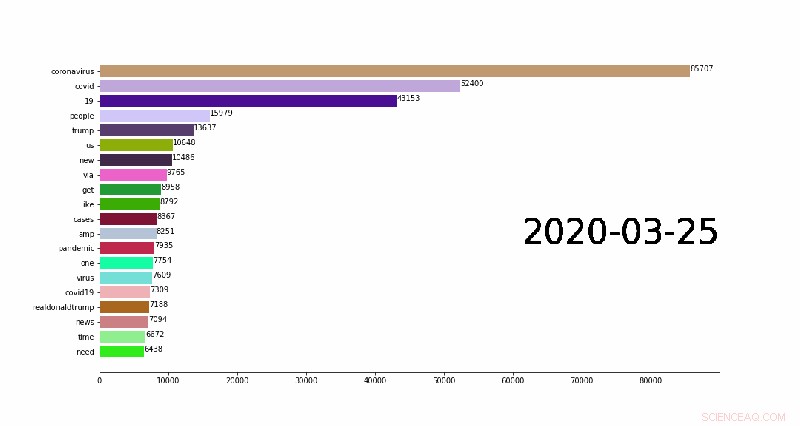
En animation som visar de 20 bästa dagliga n-grammen (vanliga ord i Twitter-inlägg) som ändrar övertid. Kredit:Weijia Xu, TACC
Dessa ansträngningar kommer att underlättas av verktyg utvecklade vid TACC, som Domäninformations- och ordförrådsextraktionsprojektet, ett National Science Foundation-finansierat försök att extrahera biologiska enheter från publikationer och andra textdokument med hjälp av maskininlärning, som har anpassats för andra typer av utsug.
TACC:s huvudmål – här, som i det mesta — är att underlätta andras forskning och kraftupptäckter. "Vi är mest intresserade av att låta människor komma åt kurerade datauppsättningar och hjälpa dem att göra forskning, " sa Xu. "Vi samlar in, städar upp, och bearbetar data så att den är redo för andra att använda."
Forskare från University of Texas i Austin (UT Austin) är bland de första som uttrycker intresse för att använda TACC COVID-19 Twitter-datauppsättningar för riktad forskning.
"The TACC COVID-19 Twitter collection will be invaluable in enabling us to model communication patterns and topics that emerge across stages of the disease, " said Sharon Stover, a professor in the Moody College of Communications. "We may be able to compare the timeline to similar data from other countries such as China that experienced the epidemic earlier. This may lead us toward understanding when typical responses occur and help us to characterize how populations make sense of health pandemics at certain stages in an epidemic's process."
Strover is particularly interested in learning how one might segment tweets by certain population features to learn more about sub-networks that pass along certain information—or ignore it.
Dhiraj Murthy, an associate professor of Journalism and Sociology at UT Austin and author of the first scholarly book about Twitter, plans to use the dataset for his academic work.
"My lab is in the very initial stages of using these data to study two research questions:To what extent is fake news, misinformation, and disinformation regarding COVID-19 present on social media platforms? And:Are social media platforms being used as venues for racist messaging against people of Chinese/Asian origin within COVID-19-related posts?"
Matt Lease, from the UT School of Information, has been using the database to research misinformation in collaboration with Murthy, and also to identify incidents of racist messaging. "The large dataset TACC is collecting, along with its computing and storage services, plus excellent researchers and staff, makes it a fantastic resource for researchers interested in studying and combatting the spread of racist messaging on Twitter."
Both in the moment, and for retrospective analyses, Twitter data can be an incredible resource.
Said TACC research associate Ruizhu Huang:"The large volume of tweets collected at TACC provides a valuable date source to explore various perspectives on COVID-19. And the storage and supercomputing power at TACC will tremendously speed up the data analysis process."














