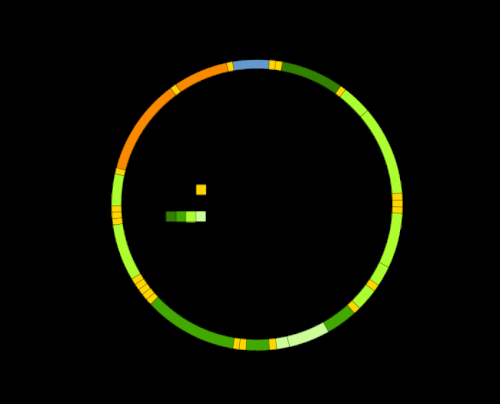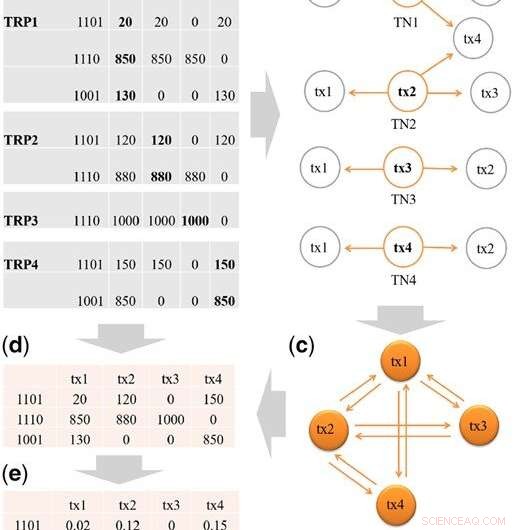
Steg för att konstruera startdesignmatrisen X. (a) TRP för tx1, tx2, tx3 och tx4, och sammanfattningen av binära beläggningsmönster från TRP:erna. Transcript tx5 klarar inte filtreringen (H = 2,5%) och filtreras bort från TRP1. I varje binärt mönster, siffra 1 betyder att det finns läsningar som kommer från en eqclass, och 0 annars. Till exempel, det finns tre eqclasses i TRP1:eqclass1, eqclass2 och eqclass3. För eq1 är det binära mönstret 1101, vilket betyder tre avskrifter, dvs tx1, tx2 och tx4 har läsningar från eq1. (b) Transcript neighbors (TN) för tx1 till tx4. (c) Illustration av konstruktionen av transkriptionskluster (TC) från TN:erna. Vi samlar först in TN för tx1, tx2, tx3 och tx4, och lägg sedan till kopplingarna mellan transkriptioner i TC. Till exempel, från TN1, vi lägger till anslutningen av tx1-tx2, tx1-tx3 och tx1-tx4. I slutet, en TC skulle innehålla alla kopplingar mellan transkript som delar exoner. (d) Den unika uppsättningen av binära mönster behålls, så tre unika mönster kvarstår:1101, 1001, 1110. Vi fyller sedan i läsvärdena från varje källa TRP. Till exempel, för mönster 1101, i TRP1 är läsantalet 20 för tx1, i TRP2 är läsantalet 120 för tx2 och i TRP4 är läsantalet 150 för tx4. (e) Den totala läsningen av varje transkript i (d) är standardiserad för att summera till 1 för att skapa startdesignmatrisen X. Kredit:DOI:10.1093/bioinformatics/btz640
Omicsteknologi med hög genomströmning har revolutionerat biologisk och biomedicinsk forskning och stora volymer omicsdata har producerats. För detta, beräkningsverktyg för att hantera och analysera omics-data har utvecklats och det finns stora utmaningar i hur man bearbetar och tolkar omics-data på bästa sätt. Wenjiang Deng har arbetat med att utveckla nya statistiska metoder och algoritmer för omics dataanalys, använda både simulerade och verkliga cancerdata för att testa metoderna.
Kan du beskriva några av resultaten i din avhandling?
Ja, i min första studie, vi identifierar flera gener förknippade med överlevnaden av neuroblastompatienter med hög risk, säger Wenjiang Deng, Ph.D. student vid institutionen för medicinsk epidemiologi och biostatistik, MEB. Neuroblastom är den vanligaste och dödligaste cancersjukdomen hos unga barn under fem år. Vi tror att våra resultat kommer att ge betydande bevis för behandling och hantering av patienter. Våra resultat kan också vara meningsfulla för att förstå sjukdomens fysiologiska mekanismer.
Hur kommer det sig att du valde att studera just detta område?
Vi lever i en era av "big data, " och high-throughput sekvenseringsdata är den dominerande "big data" inom life science. När jag först hörde begreppet omics-data, Jag blev förvånad över dess enorma volym och den stora potentialen inom medicinsk forskning. Nuförtiden är det ganska enkelt att producera sekvenseringsdata, men vi behöver fortfarande effektiva och korrekta verktyg för att analysera dem, så jag bestämde mig för att studera utvecklingen av algoritmer under min tid som doktorand. studerande.
Vad ska du göra härnäst?
Efter mitt försvar, Jag kommer att stanna i MEB ett tag för att avsluta mina manuskript. Jag åker sedan till Shenzhen, Kina, och börja arbeta i ett bioteknikföretag som syftar till att utveckla nya metoder för tidig diagnos av cancer. Jag hoppas att vårt arbete där kommer att bidra till människors allmänna hälsa.