Ett team av forskare från universitetet i Köln och universitetet i Würzburg har i träningsstudier funnit att distinktionen mellan kända och okända ord kan tränas och leder till effektivare läsning. Att känna igen ord är nödvändigt för att förstå innebörden av en text. När vi läser flyttar vi ögonen mycket effektivt och snabbt från ord till ord.
Detta läsflöde avbryts när vi stöter på ett ord vi inte känner till, en situation som är vanlig när vi lär oss ett nytt språk. Det nya språkets ord kanske ännu inte har förstås i sin helhet, och språkspecifika egenheter i stavningen behöver fortfarande internaliseras. Teamet av psykologer under ledning av juniorprofessor Dr. Benjamin Gagl från Kölns universitets fakultet för humanvetenskap har nu hittat en metod för att optimera denna process.
De aktuella forskningsresultaten publicerades i npj Science of Learning under rubriken "Undersöka lexikal kategorisering i läsning baserat på gemensamma diagnostik- och träningsmetoder för språkinlärare." Med start i maj kommer uppföljningsstudier som förlänger utbildningsprogrammet att genomföras.
"Läsning är avgörande för informationsbehandling", säger huvudförfattaren Benjamin Gagl, som har studerat de kognitiva och neurala processerna för ordigenkänning i flera år. För två år sedan visade han och ett team av forskare att i vår förståelse av de processer som implementeras i ordigenkänning, gör psykologiska teorier inte tillräckligt exakta antaganden om de exakta funktionerna hos ett av de mest frekvent aktiverade hjärnområdena i den vänstra tinningloben.
För att överbrygga denna kunskapslucka utvecklade Gagl och hans kollegor en modell som använder etablerade beteendefynd från psykologi för att förutsäga aktiveringen av detta läsområde i hjärnan; denna modell ligger till grund för det träningsprogram som beskrivs i den nya studien.
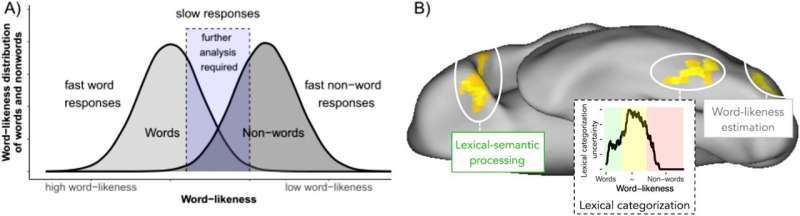
Modellen antar att denna hjärnregion fungerar som ett filter och separerar redan kända ord från irrelevanta eller ännu inte kända bokstavskombinationer; endast kända ord tillåts 'passera' för att initiera åtföljande språklig bearbetning. Men när vi stöter på ett nytt ord kan vi inte fortsätta läsa utan skulle behöva slå upp ordet i ett lexikon eller på Internet för att förstå dess betydelse.
Utbildningsprocedurerna som är centrala för den aktuella studien motiverades av antagandena i "Lexical Categorization Model". Beteendestudier visade att läsförmågan förbättrades när deltagarna tränades i denna filtreringsprocess som är central för effektiv läsning. Utbildningsproceduren innehöll enkla uppgifter där läsarna skulle skilja ord från icke-ord (t.ex. sökväg mot poth) genom att trycka på en knapp.
Efter tre träningsdagar förbättrades läsprestandan avsevärt i tre separata studier. Teamet använde också en maskininlärningsbaserad diagnostisk procedur som kan öka effektiviteten i utbildningen eftersom den kan upptäcka deltagare som sannolikt inte skulle dra nytta av vidareutbildning. Detta gör att ett individuellt beslut kan fattas för varje elev om huruvida den lexikaliska kategoriseringsutbildningen är värd ansträngningen eller om alternativ utbildning bör genomföras istället.
Som en del av ett nyförvärvet projekt som startar den 1 maj kommer forskarna att vidareutveckla datormodellerna, vilket motiverar nya träningsmetoder för språkinlärning eller för att kompensera andra lässtörningar. Utöver fältet tyska som främmande språk, kan utbildningsmetoderna potentiellt användas vid dyslexibehandling.
"Neuro-kognitiva datormodeller kan användas för att implementera grundläggande vetenskapliga rön som ska användas i individuella diagnostiska träningsprogram i utbildnings- och kliniska miljöer. Detta gör det möjligt för oss att hjälpa enskilda elever att optimera sina läsförmåga och på så sätt avsevärt förbättra sina färdigheter i informationsbehandling." sa Gagl.
Mer information: Benjamin Gagl et al, Undersöker lexikal kategorisering i läsning baserad på gemensamma diagnostiska och träningsmetoder för språkinlärare, npj Science of Learning (2024). DOI:10.1038/s41539-024-00237-7
Tillhandahålls av University of Cologne