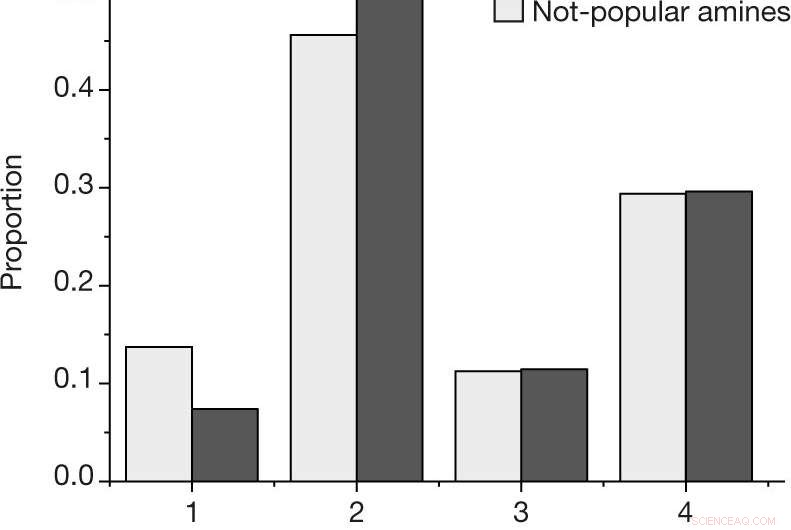
a, Andelen efter utfall för varje reaktion, med hjälp av resultatskalan som beskrivs i Metoder, för de populära och inte populära aminerna i den människovalda datauppsättningen. b, Uppskattad sannolikhet för att observera minst en lyckad reaktion (utfall 4) eller misslyckande (utfall 1, 2 och 3) för en given amin, för N =27 populära och N =28 icke-populära aminer bland de människovalda datauppsättningarna. Centervärden indikerar observerad andel av resultaten. Felfält indikerar en uppskattning av standardavvikelsen. Kreditera: Natur (2019). DOI:10.1038/s41586-019-1540-5
Ett team av materialvetare vid Haverford College har visat hur mänsklig partiskhet i data kan påverka resultaten av maskininlärningsalgoritmer som används för att förutsäga nya reagenser för att göra önskade produkter. I deras tidning publicerad i tidningen Natur , gruppen beskriver att testa en maskininlärningsalgoritm med olika typer av datamängder och vad de hittade.
En av de mer kända tillämpningarna av maskininlärningsalgoritmer är ansiktsigenkänning. Men det finns möjliga problem med sådana algoritmer. Ett sådant problem uppstår när en ansiktsalgoritm avsedd att leta efter en individ bland många ansikten har tränats med människor från bara en ras. I denna nya insats, forskarna undrade om partiskhet, oavsiktligt eller på annat sätt, kan dyka upp i algoritmresultat för maskininlärning som används i kemiapplikationer som är utformade för att leta efter nya produkter.
Sådana algoritmer använder data som beskriver ingredienserna i reaktioner som resulterar i skapandet av en ny produkt. Men data som systemet är utbildad på kan ha stor inverkan på resultaten. Forskarna noterar att för närvarande, sådana uppgifter erhålls från publicerade forskningsinsatser, vilket innebär att de vanligtvis genereras av människor. De noterar att data från sådana insatser kunde ha genererats av forskarna själva, eller av andra forskare som arbetar med separata insatser. Data kan till och med komma från en enda person som helt enkelt relaterar från minnet, eller från en professors förslag, eller en doktorand med en ljus idé. Poängen är, data kan vara partisk när det gäller resursens bakgrund.
I denna nya insats, forskarna ville veta om sådana fördomar kan påverka resultaten av maskininlärningsalgoritmer som används för kemiapplikationer. Att få reda på, de tittade på en specifik uppsättning material som kallas aminmallade vanadinborater. När de syntetiseras framgångsrikt, kristaller bildas - ett enkelt sätt att avgöra om en reaktion var framgångsrik.
Experimentet bestod i att träna en maskininlärningsalgoritm om data kring syntesen av vanadinborater, och sedan programmera systemet för att skapa sitt eget. Några av de data som samlats in av forskarna var mänskligt genererade, och en del av det samlades in slumpmässigt. De rapporterar att algoritmen som utbildats i slumpmässiga data gjorde det bättre att hitta sätt att syntetisera vanadinborater än när den använde data som genererats från människor. De hävdar att detta visar en tydlig partiskhet i data som skapades av människor.
© 2019 Science X Network