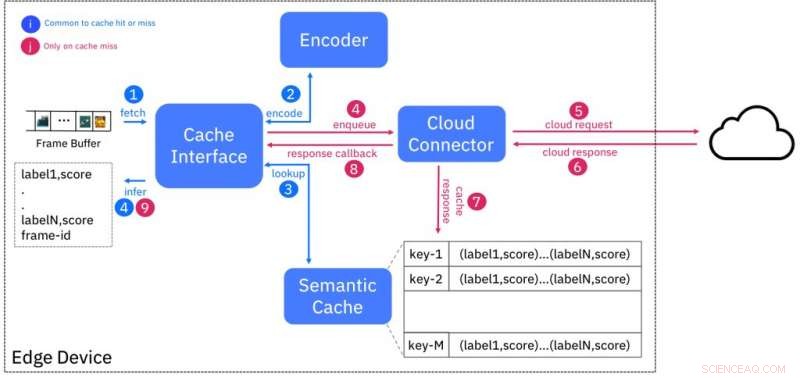
Blockschema för semantisk cachetjänst. Kredit:IBM
Tillgången till högupplösta, billiga sensorer har exponentiellt ökat mängden data som produceras, som skulle kunna överväldiga det befintliga Internet. Detta har lett till behovet av datorkapacitet för att bearbeta data nära där den genereras, i kanterna av nätverket, istället för att skicka den till molndatacenter. Edge computing, som detta är känt, minskar inte bara belastningen på bandbredden utan minskar också latensen för att erhålla intelligens från rådata. Dock, tillgången på resurser vid kanten är begränsad på grund av bristen på stordriftsfördelar som gör molninfrastruktur kostnadseffektiv att hantera och erbjuda.
Potentialen med edge computing är ingenstans mer uppenbar än med videoanalys. Högupplösta (1080p) videokameror blir vanliga inom områden som övervakning och, beroende på bildhastighet och datakomprimering, kan producera 4-12 megabit data per sekund. Nyare 4K-upplösningskameror producerar rådata i storleksordningen gigabit per sekund. Kravet på realtidsinsikter i sådana videoströmmar driver användningen av AI-tekniker som djupa neurala nätverk för uppgifter inklusive klassificering, objektdetektion och extrahering, och anomalidetektering.
I vårt Hot Edge 2018 konferensbidrag "Shadow Puppets:Cloud-level Accurate AI Inference at the Speed and Economy of Edge, "vårt team på IBM Research – Ireland utvärderade experimentellt prestandan för en sådan AI-arbetsbelastning, objektklassificering, använda kommersiellt tillgängliga molnbaserade tjänster. Det bästa resultatet vi kunde säkra var en klassificeringsutgång på 2 bilder per sekund, vilket är långt under standardvideoproduktionshastigheten på 24 bilder per sekund. Att köra ett liknande experiment på en representativ edge-enhet (NVIDIA Jetson TK1) uppnådde latenskraven men använde de flesta resurser som fanns tillgängliga på enheten i denna process.
Vi bryter denna dualitet genom att föreslå den semantiska cachen, ett tillvägagångssätt som kombinerar den låga latensen för edge-distributioner med de nästan oändliga resurserna som finns tillgängliga i molnet. Vi använder den välkända tekniken med cachning för att maskera latens genom att utföra AI-inferens för en viss ingång (t.ex. videoram) i molnet och lagra resultaten på kanten mot ett "fingeravtryck", eller en hashkod, baserat på funktioner som extraherats från indata.
Detta schema är utformat så att indata som är semantiskt lika (t.ex. tillhör samma klass) kommer att ha fingeravtryck som är "nära" varandra, enligt något avståndsmått. Figur 1 visar utformningen av cachen. Kodaren skapar fingeravtrycket för en ingångsvideoram och söker i cachen efter fingeravtryck inom ett specifikt avstånd. Om det finns en matchning, sedan tillhandahålls slutledningsresultaten från cachen, på så sätt undviker behovet av att fråga efter AI-tjänsten som körs i molnet.
Vi finner fingeravtrycken analoga med skuggdockor, tvådimensionella projektioner av figurer på en skärm skapad av ett ljus i bakgrunden. Alla som har använt sina fingrar för att skapa skuggdockor kommer att intyga att frånvaron av detaljer i dessa figurer inte begränsar deras förmåga att vara grunden för bra berättande. Fingeravtrycken är projektioner av den faktiska ingången som kan användas för rika AI-applikationer även i frånvaro av originaldetaljer.
Vi har utvecklat en komplett proof of concept implementering av den semantiska cachen, efter en "som en tjänst" designmetod, och att exponera tjänsten för användare av avancerade enheter/gatewayer via ett REST-gränssnitt. Våra utvärderingar av en rad olika edge-enheter (Raspberry Pi 3/NVIDIA Jetson TK1/TX1/TX2) har visat att latensen för slutledning har minskat med 3 gånger och bandbreddsanvändningen med minst 50 procent jämfört med en moln- enda lösningen.
Tidig utvärdering av en första prototypimplementering av vårt tillvägagångssätt visar dess potential. Vi fortsätter att mogna det initiala tillvägagångssättet, prioriterar att experimentera med alternativa kodningstekniker för förbättrad precision, samtidigt som utvärderingen utökas till ytterligare datauppsättningar och AI-uppgifter.
Vi föreställer oss att denna teknik ska ha tillämpningar i detaljhandeln, prediktivt underhåll för industrianläggningar, och videoövervakning, bland andra. Till exempel, den semantiska cachen skulle kunna användas för att lagra fingeravtryck av produktbilder vid kassorna. Detta kan användas för att förhindra butiksförluster på grund av stöld eller felskanning. Vårt tillvägagångssätt fungerar som ett exempel på att sömlöst växla mellan moln- och edge-tjänster för att leverera de bästa AI-lösningarna på kanten.
Den här historien återpubliceras med tillstånd av IBM Research. Läs originalberättelsen här.














