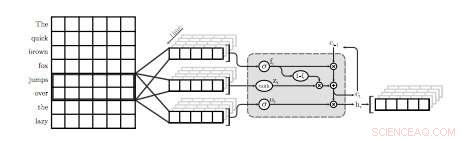
En illustration av det första QRNN -lagret för språkmodellering. I denna visualisering, ett QRNN-lager med en fönsterstorlek på två konvolverar och pooler med hjälp av inbäddningar från ingången. Observera frånvaron av återkommande vikter. Kredit:Tang &Lin.
Ett team av forskare vid University of Waterloo i Kanada har nyligen genomfört en studie som utforskar avvägningar mellan noggrannhet och effektivitet av neurala språkmodeller (NLM) som specifikt tillämpas på mobila enheter. I deras tidning, som förpublicerades på arXiv, forskarna föreslog också en enkel teknik för att återställa viss förvirring, ett mått på en språkmodells prestanda, använder en försumbar mängd minne.
NLM är språkmodeller baserade på neurala nätverk genom vilka algoritmer kan lära sig den typiska fördelningen av ordsekvenser och göra förutsägelser om nästa ord i en mening. Dessa modeller har ett antal användbara tillämpningar, till exempel, möjliggör smartare mjukvarutangentbord för mobiltelefoner eller andra enheter.
"Neurala språkmodeller (NLMs) existerar i ett avvägningsutrymme för noggrannhet och effektivitet där bättre förvirring vanligtvis kommer till priset av större beräkningskomplexitet, "skrev forskarna i sin uppsats." I ett tangentbordsprogram på mobila enheter, detta leder till högre strömförbrukning och kortare batteritid. "
När den appliceras på mjukvarutangentbord, NLM:er kan leda till mer exakt förutsägelse av nästa ord, tillåter användare att mata in nästa ord i en given mening med ett enda tryck. Två befintliga applikationer som använder neurala nätverk för att tillhandahålla denna funktion är SwiftKey1 och Swype2. Dock, dessa applikationer kräver ofta mycket kraft för att fungera, snabbt tömma batterierna i mobila enheter.
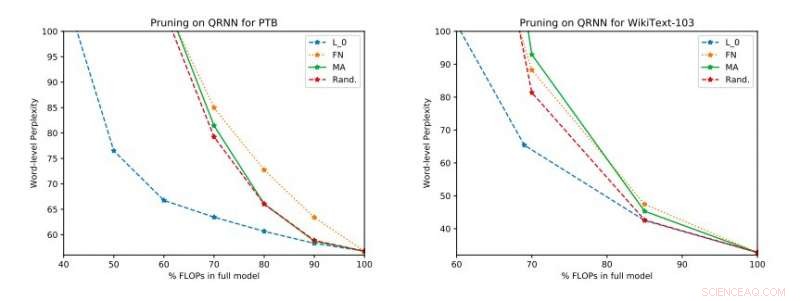
Fullständiga experimentella resultat på Penn Treebank och WikiText-103. Vi illustrerar avvägningsutrymmet mellan förvirring och effektivitet i testsetet som erhölls innan uppdateringen med en ranking tillämpades. Upphovsman:Tang &Lin.
"Baserat på standardmått som förvirring, neurala tekniker representerar ett framsteg i den senaste språkmodelleringen, " förklarade forskarna i sin uppsats. "Bättre modeller, dock, komma till en kostnad i beräkningskomplexitet, vilket leder till högre strömförbrukning. I samband med mobila enheter, energieffektivitet är, självklart, ett viktigt optimeringsmål."
Enligt forskarna, NLM har hittills främst utvärderats i samband med bildigenkänning och sökordsspotting, medan deras noggrannhetseffektivitet avvägning i Natural Language Processing (NLP) applikationer ännu inte har undersökts noggrant. Deras studie fokuserar på detta outforskade forskningsområde, utföra en utvärdering av NLM och deras avvägningar mellan exakthet och effektivitet på en Raspberry Pi.
"Våra empiriska utvärderingar tar hänsyn till både förvirring och energiförbrukning på en Raspberry Pi, där vi visar vilka metoder som ger den bästa driftpunkten för förvirring och energiförbrukning, " sa forskarna. "Vid en operationspunkt, en av teknikerna kan ge energibesparingar på 40 procent jämfört med de senaste [metoderna] med endast en 17 procents relativ ökning av förvirring."
I sin studie, forskarna utvärderade också ett antal inferens-tidsbeskärningstekniker på kvasi-recurrenta neurala nätverk (QRNN). Utöka användbarheten av befintliga metoder för beskärning av träningstid till QRNN under körning, de uppnådde flera arbetspunkter inom avvägningsutrymmet för noggrannhet och effektivitet. För att förbättra prestanda med en liten mängd minne, de föreslog träning och lagring av enkelviktsuppdateringar vid önskade arbetspunkter.
© 2018 Tech Xplore














