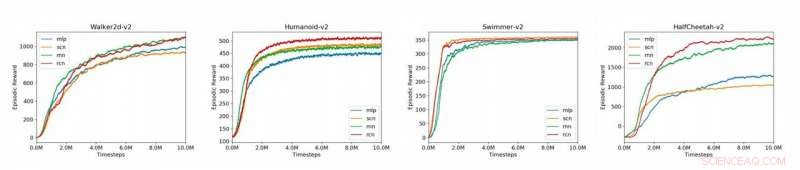
Plots som jämför baslinjemodellerna (MLP, SCN, RNN, RCN) för de 4 MuJoCo-miljöerna som presenteras i uppsatsen (Humanoid-v2, HalfCheetah-v2, Walker2d-v2, Simmare-v2). Kredit:Liu et al.
Centrala mönstergeneratorer (CPG) är biologiska neurala kretsar som kan producera koordinerade rytmiska utgångar utan att behöva rytmiska ingångar. CPG:er är ansvariga för de flesta rytmiska rörelser som observeras i levande organismer, som att gå, andas eller simmar.
Verktyg för att effektivt modellera rytmiska utsignaler när de ges arytmiska indata kan ha viktiga tillämpningar inom en mängd olika områden, inklusive neurovetenskap, robotik och medicin. I förstärkningsinlärning, de flesta befintliga nät som används för att modellera lokuppgifter, såsom multilayer perceptron (MLP) baslinjemodeller, misslyckas med att generera rytmiska utgångar i frånvaro av rytmiska ingångar.
Nyligen genomförda studier har föreslagit användning av arkitekturer som kan dela upp ett nätverks policy i linjära och olinjära komponenter, såsom strukturerade kontrollnät (SCN), som visade sig överträffa MLPs i en mängd olika miljöer. En SCN består av en linjär modell för lokal styrning och en olinjär modul för global styrning, vars resultat kombineras för att skapa den politiska åtgärden. Bygger på tidigare arbete med återkommande neurala nätverk (RNN) och SCN, ett team av forskare vid Stanford University har nyligen utarbetat ett nytt tillvägagångssätt för att modellera CPG:er i förstärkningsinlärning.
"CPG är biologiska neurala kretsar som kan producera rytmiska utsignaler i frånvaro av rytmisk input, "Ademi Adeniji, en av forskarna som genomförde studien, berättade Tech Xplore. "Befintliga tillvägagångssätt för att modellera CPG:er i förstärkningsinlärning inkluderar multilayer perceptron (MLP), en enkel, fullt anslutet neuralt nätverk, och det strukturerade kontrollnätet (SCN), som har separata moduler för lokal och global kontroll. Vårt forskningsmål var att förbättra dessa baslinjer genom att låta modellen fånga tidigare observationer, vilket gör den mindre benägen för fel från ingångsbrus."

Skärmdump av HalfCheetah-miljön. Kredit:Liu et al.
Det återkommande kontrollnätet (RCN) som utvecklats av Adeniji och hans kollegor antar arkitekturen för ett SCN, men använder en vanilj RNN för global kontroll. Detta gör att modellen kan förvärva lokala, global och tidsberoende kontroll.
"Som SCN, vår RCN delar upp informationsflödet i linjära och olinjära moduler, " Nathaniel Lee, en av forskarna som genomförde studien, berättade TechXplore. "Intuitivt, den linjära modulen, faktiskt en linjär transformation, lär sig lokala interaktioner, medan den olinjära modulen lär sig globala interaktioner."
SCN-metoder använder en MLP som sin olinjära modul, medan RCN utarbetat av forskarna ersätter denna modul med en RNN. Som ett resultat, deras modell får ett "minne" av tidigare observationer, kodad av RNN:s dolda tillstånd, som den sedan använder för att generera framtida åtgärder.
Forskarna utvärderade sitt tillvägagångssätt på OpenAI Gym-plattformen, en fysikmiljö för förstärkningslärande, samt på multi-joint dynamik med kontrakt (Mu-JoCo) uppgifter. Deras RCN antingen matchade eller överträffade andra baslinje MLP och SCN i alla testade miljöer, effektivt lära sig lokal och global kontroll samtidigt som man skaffar mönster från tidigare sekvenser.

Skärmdump av Humanoid -miljön. Kredit:Liu et al.
"CPG är ansvariga för ett stort antal rytmiska biologiska mönster, "Jason Zhao, en annan forskare involverad i studien, sa. "Möjligheten att modellera CPG -beteende kan framgångsrikt tillämpas på områden som medicin och robotik. Vi hoppas också att vår forskning kommer att belysa effekten av lokal/global kontroll samt återkommande arkitekturer för modellering av central mönstergenerering i förstärkningslärande."
Resultaten som samlats in av forskarna bekräftar potentialen hos SCN-liknande strukturer för att modellera CPG för förstärkningslärande. Deras studie tyder också på att RNN:er är särskilt effektiva för att modellera lokomotivuppgifter och att separering av linjära och olinjära styrmoduler avsevärt kan förbättra en modells prestanda.
"Än så länge, vi tränade bara vår modell med hjälp av evolutionära strategier (ES), en off-gradient optimizer, sa Vincent Liu, en av forskarna som deltar i studien. "I framtiden, vi planerar att utforska dess prestanda när vi utbildar den med proximal policyoptimering (PPO), en on-gradient optimizer. Dessutom, framsteg inom naturlig språkbehandling har visat att konvolutionella neurala nätverk är effektiva substitut till återkommande neurala nätverk, både i prestanda och beräkning. Vi kan därför överväga att experimentera med en tidsfördröjd neural nätverksarkitektur, som tillämpar 1-D faltning längs tidsaxeln för tidigare observationer."
© 2019 Science X Network














