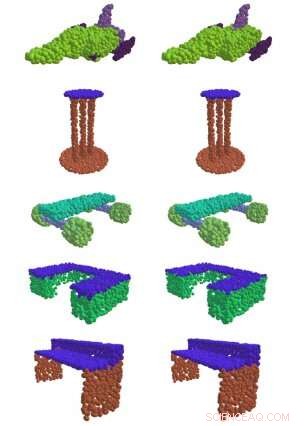
Till vänster, EdgeConv, en metod utvecklad vid MIT, lyckas hitta meningsfulla delar av 3D-former, som ytan på ett bord, flygplanets vingar, och hjul på en skateboard. Till höger är jämförelsen mellan grund och sanning. Kredit:Massachusetts Institute of Technology
Om du någonsin har sett en självkörande bil i det vilda, du kanske undrar om den snurrande cylindern ovanpå den.
Det är en "lidarsensor, " och det är det som gör att bilen kan navigera i världen. Genom att sända ut pulser av infrarött ljus och mäta tiden det tar för dem att studsa mot föremål, sensorn skapar ett "punktmoln" som bygger en 3D-ögonblicksbild av bilens omgivning.
Det är svårt att förstå rå punkt-molndata, och före maskininlärningsåldern krävde det traditionellt att högutbildade ingenjörer mödosamt specificerade vilka egenskaper de ville fånga för hand. Men i en ny serie artiklar från MIT:s datavetenskap och artificiell intelligens Laboratory (CSAIL), forskare visar att de kan använda djupinlärning för att automatiskt bearbeta punktmoln för ett brett utbud av 3D-avbildningstillämpningar.
"Inom datorseende och maskininlärning idag, 90 procent av framstegen handlar bara om tvådimensionella bilder, "säger MIT -professor Justin Solomon, som var seniorförfattare till den nya serien av uppsatser som leddes av Ph.D. student Yue Wang. "Vårt arbete syftar till att möta ett grundläggande behov av att bättre representera 3D-världen, med tillämpning inte bara i autonom körning, men alla fält som kräver förståelse av 3D-former."
De flesta tidigare tillvägagångssätt har inte varit särskilt framgångsrika när det gäller att fånga mönstren från data som behövs för att få meningsfull information ur en massa 3D-punkter i rymden. Men i en av lagets tidningar, de visade att deras "EdgeConv" -metod för att analysera punktmoln med hjälp av en typ av neurala nätverk som kallas ett dynamiskt grafkonvolutionellt neuralt nätverk tillät dem att klassificera och segmentera enskilda objekt.
"Genom att bygga "grafer" över närliggande punkter, Algoritmen kan fånga hierarkiska mönster och därför härleda flera typer av generisk information som kan användas av en myriad av nedströmsuppgifter, säger Wadim Kehl, en maskininlärningsforskare vid Toyota Research Institute som inte var involverad i arbetet.
Förutom att utveckla EdgeConv, teamet utforskade också andra specifika aspekter av punktmolnbearbetning. Till exempel, en utmaning är att de flesta sensorer ändrar perspektiv när de rör sig i 3D-världen; varje gång vi tar en ny skanning av samma objekt, dess position kan vara annorlunda än förra gången vi såg den. För att slå samman flera punktmoln till en enda detaljerad vy av världen, du måste rikta in flera 3D-punkter i en process som kallas "registrering".
Registrering är avgörande för många former av bildbehandling, från satellitdata till medicinska ingrepp. Till exempel, när en läkare måste ta flera magnetiska resonanstomografiska skanningar av en patient över tid, registrering är det som gör det möjligt att anpassa skanningarna för att se vad som har ändrats.
"Registrering är det som gör att vi kan integrera 3D-data från olika källor i ett gemensamt koordinatsystem, " säger Wang. "Utan det, vi skulle faktiskt inte kunna få så meningsfull information från alla dessa metoder som har utvecklats. "
Solomon och Wangs andra artikel demonstrerar en ny registreringsalgoritm som kallas "Deep Closest Point" (DCP) som visade sig bättre hitta ett punktmolns särskiljande mönster, poäng, och kanter (kända som "lokala särdrag") för att anpassa det med andra punktmoln. Detta är särskilt viktigt för sådana uppgifter som att göra det möjligt för självkörande bilar att placera sig i en scen ("lokalisering"), samt för robothänder för att lokalisera och greppa enskilda föremål.
En begränsning av DCP är att den förutsätter att vi kan se en hel form istället för bara en sida. Detta innebär att den inte kan hantera den svårare uppgiften att justera partiella vyer av former (känd som "partiell-till-partiell registrering"). Som ett resultat, i en tredje artikel presenterade forskarna en förbättrad algoritm för denna uppgift som de kallar Partial Registration Network (PRNet).
Solomon säger att befintlig 3D-data tenderar att vara "ganska rörig och ostrukturerad jämfört med 2-D-bilder och fotografier." Hans team försökte ta reda på hur man kan få meningsfull information ur all den oorganiserade 3D-data utan den kontrollerade miljön som många maskininlärningstekniker nu kräver.
En viktig observation bakom framgången med DCP och PRNet är idén att en kritisk aspekt av punktmolnbearbetning är sammanhang. De geometriska särdragen på punktmoln A som föreslår de bästa sätten att rikta in den till punktmoln B kan skilja sig från de särdrag som behövs för att anpassa den till punktmoln C. Till exempel, i delregistrering, en intressant del av en form i ett punktmoln kanske inte syns i det andra, vilket gör den värdelös för registrering.
Wang säger att teamets verktyg redan har implementerats av många forskare inom datorvisionssamhället och utanför. Även fysiker använder dem för en applikation som CSAIL -teamet aldrig hade övervägt:partikelfysik.
Går vidare, forskarna hoppas kunna använda algoritmerna på verkliga data, inklusive data som samlats in från självkörande bilar. Wang säger att de också planerar att utforska potentialen i att träna sina system med hjälp av självövervakat lärande, för att minimera mängden mänskliga kommentarer som behövs.
Den här historien återpubliceras med tillstånd av MIT News (web.mit.edu/newsoffice/), en populär webbplats som täcker nyheter om MIT-forskning, innovation och undervisning.