Kredit:Garg et al.
Framsteg inom robotik och artificiell intelligens (AI) möjliggör utvecklingen av artificiella medel utformade för att hjälpa människor i en mängd olika vardagsmiljöer. En av de många möjliga användningsområdena för dessa system kan vara att eskortera människor eller värdefulla varor som överförs från en plats till en annan, försvara dem från hot eller attacker.
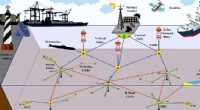
Fascinerad av denna idé, ett team av forskare vid University of New Mexico har nyligen introducerat en ny end-to-end-lösning för att koordinera robotiska eskortteam som skyddar högvärdiga nyttolaster eller varor. Tekniken de föreslog, presenteras i en tidning förpublicerad på arXiv, bygger på djup förstärkningsinlärning (RL), vilket innebär att träna algoritmer för att göra effektiva förutsägelser genom att analysera data.
"Jag kom först på idén bakom den här studien när jag tänkte släpa min resväska genom en fullsatt flygplats, "Lydia Tapia, huvudforskaren i studien, berättade för TechXplore. "Jag tänkte för mig själv:Tänk om det kunde hjälpa min navigering genom att stanna hos mig och vakta mig när jag gick?"
Innan de började utveckla sin lösning för att koordinera defensiva eskortteam, Tapia och hennes team granskade tidigare litteratur och letade efter inspiration eller liknande tillvägagångssätt. Tyvärr, dock, de kunde inte hitta andra studier där robotar användes för att förutsäga inkommande hot och avlyssna dem, skydda mänskliga användare och se till att de nådde sin destination säkert.
"Det är mycket arbete med navigationsassistenter, men oftast fungerar de genom att slå ett larm för att hindra en person från att navigera nära ett inkommande hot, Tapia förklarade. "Vi fann att ett roboteskortteam kunde ha flera andra tillämpningar i säkerhetskritiska scenarier, mycket viktigare än min flygplatsresväska, så vi fokuserade den här uppsatsen på lastnavigering, vilket är en vanlig uppgift där eskorter håller nyttolasten säker när de navigerar."
Tapia och hennes kollegor tränade sin djupa RL-modell för att förutsäga effektiva positioner och strategier för att fånga upp möjliga hot. Liksom andra RL-tekniker, under träning, deras modell gick igenom en lång rad rättegångar där den var tvungen att föreslå åtgärder för att avlyssna hot och samordna eskorter, ta emot belöningar när strategin den föreslog var effektiv. Över tid, modellen lärde sig att generalisera vad den lärde sig under träningen och tillämpa det på helt nya situationer.
"Det finns för närvarande inga befintliga intelligenta metoder för att lösa detta problem, så vi visade hur agenter med en fast position kan användas, " sa Tapia. "Men, som du kan föreställa dig, du skulle behöva en hel del defensiva agenter placerade på vanliga positioner för att skydda en navigerande nyttolast."
Forskarna utvärderade sin RL-teknik i en serie simuleringar där eskortagenter skyddar ett specifikt mål från hot eller hinder i den omgivande miljön. De fann att deras modell överträffade de senaste algoritmerna för att undvika hinder, öka navigeringsframgången med upp till 31 procent. Dessutom, eskortteamen som koordinerades med deras teknik visade sig framgångsrikt skydda nyttolaster med en framgångsfrekvens som var 75 procent högre än den som eskortteam uppnådde i statiska formationer.
"Det mest meningsfulla resultatet av vårt arbete var att kunna representera problemet på ett sätt som är möjligt för agenten att lära sig en lösning som är flexibel, även med tanke på oväntade omständigheter som att medel tas bort eller läggs till, " förklarade Tapia.
I framtiden, tillvägagångssättet som utvecklats av Tapia och hennes team vid University of New Mexico skulle kunna användas för att samordna team som eskorterar nyttolaster eller mänskliga resenärer. Dock, det kan också ha andra applikationer, till exempel att hjälpa utvecklingen av nya verktyg för att hjälpa och eskortera synskadade personer när de reser eller navigerar i okända miljöer.
"Vi är glada över att undersöka ytterligare tillämpningar av detta arbete för nya problem som vi ännu inte har löst, "Sade Tapia. "Det skulle vara trevligt att också se våra intelligenta agenter demonstreras på hårdvara."
© 2019 Science X Network