
Kredit:Gupta et al.
Reinforcement learning (RL) är en allmänt använd maskininlärningsteknik som innebär att man tränar AI-agenter eller robotar med hjälp av ett system för belöning och bestraffning. Än så länge, forskare inom robotikområdet har i första hand tillämpat RL-tekniker i uppgifter som genomförs under relativt korta tidsperioder, som att röra sig framåt eller ta tag i föremål.
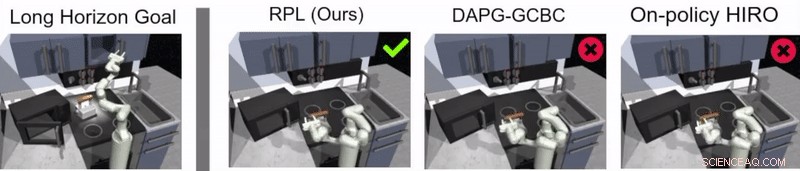
Ett team av forskare vid Google och Berkeley AI Research har nyligen utvecklat ett nytt tillvägagångssätt som kombinerar RL med lärande genom imitation, en process som kallas reläpolicyinlärning. Detta tillvägagångssätt, introducerades i ett dokument som förpublicerats på arXiv och presenterades vid Conference on Robot Learning (CoRL) 2019 i Osaka, kan användas för att utbilda konstgjorda medel för att ta itu med flerstegs- och långhorisontuppgifter, såsom objektmanipuleringsuppgifter som sträcker sig över längre tidsperioder.
"Vår forskning kommer från många, mestadels misslyckat, experiment med mycket långa uppgifter med hjälp av förstärkningsinlärning (RL), "Abhishek Gupta, en av forskarna som genomförde studien, berättade för TechXplore. "I dag, RL i robotik tillämpas mestadels i uppgifter som kan utföras på kort tid, som att greppa, skjuta föremål, går framåt, etc. Även om dessa applikationer har ett stort värde, vårt mål var att tillämpa förstärkningsinlärning på uppgifter som kräver flera delmål och fungerar på mycket längre tidsskalor, som att duka ett bord eller städa ett kök."
Innan de började utveckla sitt tillvägagångssätt, Gupta och hans kollegor granskade tidigare litteratur för att försöka avgöra varför längre uppgifter är särskilt svåra att ta itu med med nuvarande RL-tekniker. I deras tidning, de antyder att det generellt finns två huvudorsaker till detta.
Först, det är svårt för en robot att hitta optimala lösningar för att lösa långa och komplexa uppgifter på egen hand. Andra, det är svårt för agenten att framgångsrikt ta itu med en lång uppgift för vilken feedback ges först i slutet av en lång sekvens. Reläpolicyinlärning, det nya sättet att lära som de presenterade, är utformad för att möta båda dessa utmaningar direkt.
Kredit:Gupta et al.
"För att ta itu med utmaningen att låta robotar lösa uppgifter med lång horisont på egen hand, vi bestämde oss för att förenkla problemet och använda mänskliga demonstrationer, Gupta sa. "Att lösa långa uppgifter är svårt eftersom det är extremt svårt att låta en robot upptäcka ett intressant beteende på egen hand - demonstrationer som tillhandahålls av människor kan användas som en riktlinje för intressanta saker att göra i en miljö."
Metoden för robotinlärning som föreslagits av Gupta och hans kollegor har två distinkta steg, en där en agent lär sig genom att imitera människor och den andra baserad på RL. I imitationsinlärningsstadiet, en robot matas med mänskliga demonstrationer av hur man slutför en uppgift och producerar målbetingade hierarkiska policyer.
I deras studie, forskarna använde sitt tillvägagångssätt för att träna ett konstgjort medel som heter Franka på flerstegs- och långhorisontsmanipulationsuppgifter i en simulerad köksmiljö, som modellerades med hjälp av fysiksimulatorplattformen MuJoCo. Denna miljö bestod av ett kök med en öppningsbar mikrovågsugn, fyra ugnsbrännare, en ugnsljusströmbrytare, en kittel, två gångjärnsskåp och en skjutskåpsdörr.

Kredit:Gupta et al.
"Viktigt, Att lära sig från demonstrationer enbart är inte tillräckligt för att lösa de utmanande uppgifterna i vår simulerade köksmiljö, "Karol Hausman, en annan forskare involverad i studien, berättade för TechXplore. "För att förbättra denna initiala lösning, vi låter robotarna öva på uppgifterna på egen hand för att ytterligare förfina sina beteenden."
Väsentligen, genom att använda den metod för reläpolicyinlärning som forskarna föreslagit, en agent lär sig initialt genom att bearbeta mänskliga demonstrationer av hur man slutför en given uppgift och fortsätter sedan att lära sig på egen hand via RL. För att göra processen att lära sig långsiktiga policyer lättare, teamet använde en ny dataommärkningsalgoritm som låter en agent lära sig målbetingade hierarkiska policyer.
"För att ta itu med utmaningen med sparsam feedback, vi använder en hierarkisk struktur för våra kontrollpolicyer:Högnivåpolicyn föreslår mål som lågnivåpolicyn försöker uppnå – till exempel, stäng ett skåp, stäng av brännaren, etc., Hausman förklarade. "På detta sätt, uppgiften kan lätt delas upp i mindre delproblem som kan lösas med förstärkningsinlärning som är uppbyggd av demonstrationer som tillhandahålls av människor."

Kredit:Gupta et al.
Guppta, Hausman och deras kollegor utvärderade effektiviteten av reläpolicyinlärning för att träna robotar i långa uppgifter inom den simulerade köksmiljön som de skapade, uppnå mycket lovande resultat. De fann att med rätt policystruktur och demonstrationsdata, deras tillvägagångssätt gjorde det möjligt för robotar att ta sig an mycket längre horisontuppgifter än de först trodde var möjligt.
"Vi hoppas att våra rön kan öppna upp nya vägar för att kombinera forskning om imitation och förstärkningsinlärning och ger oss en potentiell riktning som kan tillåta robotar att prestera länge, komplexa uppgifter, sa Hausman.
I framtiden, den reläpolitiska inlärningsmetod som introducerades av Gupta, Hausman och deras kollegor skulle kunna användas för att utbilda robotar i ett bredare utbud av långa uppgifter. Forskarna har hittills bara testat sin teknik i en simulerad miljö; Således, det skulle vara intressant att utvärdera det i verkliga miljöer och se om det ger lika lovande resultat.
"Som ett nästa steg, vi skulle vilja undersöka problemet med generalisering bortom demonstrationsdata, sa Hausman. Så småningom, vi skulle också vilja förbättra vår metods dataeffektivitet ytterligare, flytta till pixelobservationer och möjliggör lärande i verkligheten på en fysisk robot."
© 2019 Science X Network














