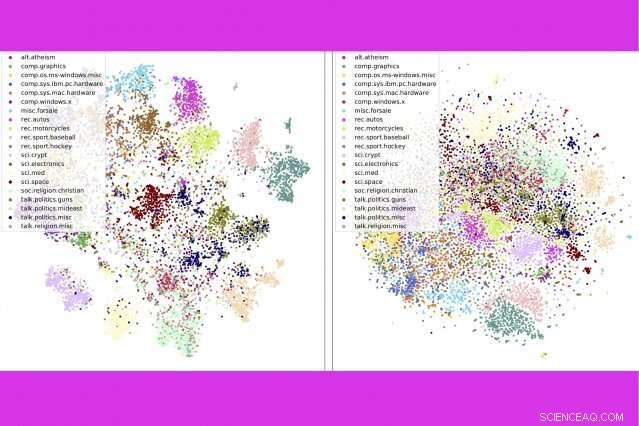
I en ny studie, forskare vid MIT och IBM kombinerar tre populära textanalysverktyg - ämnesmodellering, ordinbäddningar, och optimal transport — för att jämföra tusentals dokument per sekund. Här, de visar att deras metod (vänster) grupperar nyhetsgruppsinlägg efter kategori mer än en konkurrerande metod. Kredit:Massachusetts Institute of Technology
Med miljarder böcker, nyhetsartiklar, och dokument online, det har aldrig funnits en bättre tid att läsa – om du har tid att sålla igenom alla alternativ. "Det finns massor av text på internet, säger Justin Solomon, en biträdande professor vid MIT. "Allt som hjälper till att skära igenom allt det där materialet är extremt användbart."
Med MIT-IBM Watson AI Lab och hans Geometric Data Processing Group vid MIT, Solomon presenterade nyligen en ny teknik för att skära igenom enorma mängder text vid konferensen om neurala informationsbehandlingssystem (NeurIPS). Deras metod kombinerar tre populära textanalysverktyg – ämnesmodellering, ordinbäddningar, och optimal transport – för att leverera bättre, snabbare resultat än konkurrerande metoder på ett populärt riktmärke för klassificering av dokument.
Om en algoritm vet vad du gillade tidigare, den kan skanna miljontals möjligheter för något liknande. I takt med att naturliga språkbehandlingstekniker förbättras, dessa "du kanske också gillar"-förslagen blir snabbare och mer relevanta.
I metoden som presenterades på NeurIPS, en algoritm sammanfattar en samling av, säga, böcker, till ämnen baserade på vanliga ord i samlingen. Den delar sedan upp varje bok i sina fem till 15 viktigaste ämnen, med en uppskattning av hur mycket varje ämne totalt sett bidrar till boken.
För att jämföra böcker, forskarna använder två andra verktyg:ordinbäddningar, en teknik som förvandlar ord till listor med siffror för att återspegla deras likhet i populär användning, och optimal transport, ett ramverk för att beräkna det mest effektiva sättet att flytta objekt – eller datapunkter – mellan flera destinationer.
Ordinbäddningar gör det möjligt att utnyttja optimal transport två gånger:först för att jämföra ämnen inom samlingen som helhet, och då, i vilket par böcker som helst, för att mäta hur nära vanliga teman överlappar varandra.
Tekniken fungerar särskilt bra när man skannar stora samlingar av böcker och långa dokument. I studien, forskarna ger exemplet med Frank Stocktons "The Great War Syndicate, " en amerikansk 1800-talsroman som förutsåg uppkomsten av kärnvapen. Om du letar efter en liknande bok, en ämnesmodell skulle hjälpa till att identifiera de dominerande teman som delas med andra böcker – i det här fallet, nautisk, elementär, och martial.
Men en ämnesmodell ensam skulle inte identifiera Thomas Huxleys föreläsning från 1863, "Den ekologiska naturens tidigare tillstånd, " som en bra match. Författaren var en förkämpe för Charles Darwins evolutionsteori, och hans föreläsning, späckad med omnämnanden av fossiler och sedimentering, reflekterade framväxande idéer om geologi. När teman i Huxleys föreläsning matchas med Stocktons roman via optimal transport, några tvärgående motiv dyker upp:Huxleys geografi, flora/fauna, och kunskapsteman ligger nära Stocktons nautiska, elementär, och kampteman, respektive.
Modellera böcker efter deras representativa ämnen, snarare än enskilda ord, gör jämförelser på hög nivå möjliga. "Om du ber någon att jämföra två böcker, de delar upp var och en i lättförståeliga begrepp, och sedan jämföra begreppen, " säger studiens huvudförfattare Mikhail Yurochkin, en forskare vid IBM.
Resultatet är snabbare, mer exakta jämförelser, visar studien. Forskarna jämförde 1, 720 par böcker i Gutenberg Project dataset på en sekund – mer än 800 gånger snabbare än den näst bästa metoden.
Tekniken gör också ett bättre jobb med att noggrant sortera dokument än rivaliserande metoder – till exempel, gruppera böcker i Gutenberg-dataset efter författare, produktrecensioner på Amazon per avdelning, och BBC sportberättelser per sport. I en serie visualiseringar, författarna visar att deras metod prydligt grupperar dokument efter typ.
Förutom att kategorisera dokument snabbt och mer exakt, Metoden ger ett fönster in i modellens beslutsprocess. Genom listan över ämnen som visas, användare kan se varför modellen rekommenderar ett dokument.
Den här historien återpubliceras med tillstånd av MIT News (web.mit.edu/newsoffice/), en populär webbplats som täcker nyheter om MIT-forskning, innovation och undervisning.