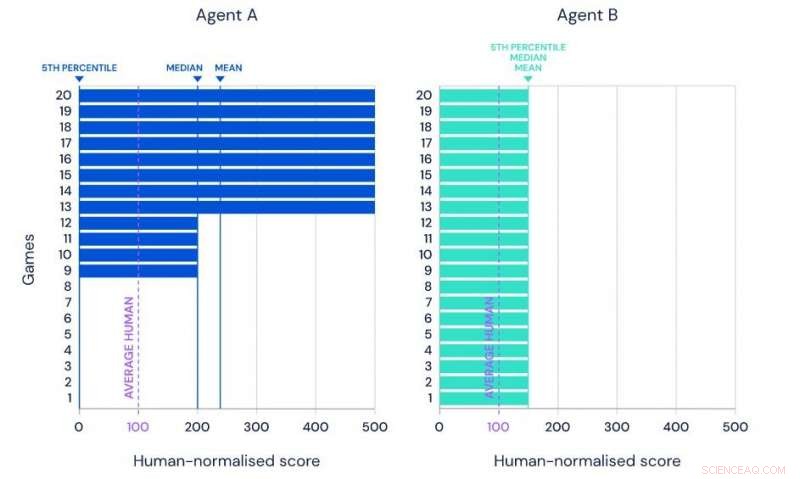
Illustration av medelvärdet, median- och 5:e percentilprestanda för två hypotetiska medel på samma referensuppsättning med 20 uppgifter. Kredit:Google
För att bättre lösa komplexa utmaningar i början av 2000-talets tredje decennium, Alphabet Inc. har utnyttjat reliker från 1980-talet:videospel.
Googles moderbolag rapporterade denna vecka att dess DeepMind Technologies Artificial Intelligence-enhet framgångsrikt har lärt sig hur man spelar 57 Atari-videospel. Och datorsystemet spelar bättre än någon människa.
Atari, skaparen av Pong, ett av de första framgångsrika tv-spelen på 1970-talet, fortsatte med att popularisera många av de stora tidiga klassiska videospelen in på 1990-talet. Videospel används ofta med AI-projekt eftersom de utmanar algoritmer för att navigera i allt mer komplexa vägar och alternativ, allt samtidigt som man möter föränderliga scenarier, hot och belöningar.
Döpt till AGENT57, Alphabets AI-system undersökte 57 ledande Atari-spel som täcker ett stort antal svårighetsgrader och varierande framgångsstrategier.
"Spel är en utmärkt testplats för att bygga adaptiva algoritmer, " sa forskarna i en rapport på bloggsidan DeepMind. "De tillhandahåller en rik uppsättning uppgifter som spelare måste utveckla sofistikerade beteendestrategier för att bemästra, men de ger också ett enkelt framstegsmått — spelresultat — att optimera mot.
"Det slutliga målet är inte att utveckla system som utmärker sig i spel, utan snarare att använda spel som en språngbräda för att utveckla system som lär sig att utmärka sig i en bred uppsättning utmaningar, "stod det i rapporten.
DeepMinds AlphaGo-system fick stort erkännande 2016 när det slog världsmästaren Lee Sedol i det strategiska spelet Go.
Bland den nuvarande skörden av 57 Atari-spel, fyra anses vara särskilt svåra för AI-projekt att bemästra:Montezuma's Revenge, Fälla, Solaris och skidåkning. De två första spelen utgör vad DeepMind kallar det förbryllande "utforsknings-exploateringsproblemet".
"Ska man fortsätta utföra beteenden man vet fungerar (utnyttja), eller ska man prova något nytt (utforska) för att upptäcka nya strategier som kan vara ännu mer framgångsrika?" frågar DeepMind. "T.ex. ska man alltid beställa samma favoriträtt på en lokal restaurang, eller prova något nytt som kanske överträffar den gamla favoriten? Utforskning innebär att vidta många suboptimala åtgärder för att samla in den information som krävs för att upptäcka ett i slutändan starkare beteende."
De andra två utmanande spelen kräver långa väntetider mellan utmaningar och belöningar, gör det svårare för AI-system att framgångsrikt analysera.
Tidigare försök att bemästra de fyra spelen med AI misslyckades alla.
Rapporten säger att det fortfarande finns utrymme för förbättringar. För en, långa beräkningstider är fortfarande ett problem. Också, samtidigt som jag erkänner att "ju längre den tränade, ju högre poängen blev, "DeepMind-forskare vill att Agent57 ska göra det bättre. De vill att det ska bemästra flera spel samtidigt; för närvarande, den kan bara lära sig ett spel åt gången och den måste genomgå träning varje gång den startar om ett spel.
I sista hand, DeepMind-forskare förutser ett program som kan tillämpa mänskliga beslutsfattande val samtidigt som de möter ständigt föränderliga och tidigare osynliga utmaningar.
"Verklig mångsidighet, som kommer så lätt för ett mänskligt spädbarn, är fortfarande långt bortom AIs räckhåll, ", avslutades rapporten.
© 2020 Science X Network