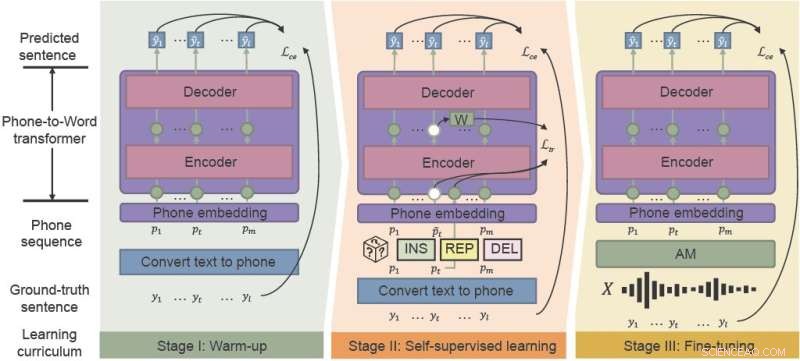
Ramverket för fonetisk-semantisk förträning (PSP) använder "brusmedveten läroplan" för att effektivt förbättra prestandan för ASR i bullriga miljöer. integrera uppvärmning, självövervakad inlärning och finjustering. Kredit:CAAI Artificial Intelligence Research , Tsinghua University Press
Populära röstassistenter som Siri och Amazon Alexa har introducerat automatisk taligenkänning (ASR) för en bredare allmänhet. Även om de är under årtionden kämpar ASR-modeller med konsekvens och tillförlitlighet, särskilt i bullriga miljöer. Kinesiska forskare utvecklade ett ramverk som effektivt förbättrar prestandan hos ASR för kaoset i vardagliga akustiska miljöer.
Forskare från Hong Kong University of Science and Technology och WeBank föreslog ett nytt ramverk – fonetisk-semantisk förträning (PSP) och demonstrerade robustheten hos deras nya modell mot syntetiska mycket bullriga taldataset.
Deras studie publicerades i CAAI Artificial Intelligence Research den 28 augusti.
"Robusthet är en långvarig utmaning för ASR", säger Xueyang Wu från Hong Kong University of Science and Technology Department of Computer Science and Engineering. "Vi vill öka robustheten hos det kinesiska ASR-systemet till en låg kostnad."
ASR använder maskininlärning och andra artificiella intelligenstekniker för att automatiskt översätta tal till text för användningar som röstaktiverade system och transkriptionsprogram. Men nya konsumentfokuserade applikationer kräver i allt högre grad att röstigenkänning ska fungera bättre – hantera fler språk och accenter och prestera mer tillförlitligt i verkliga situationer som videokonferenser och liveintervjuer.
Traditionellt kräver utbildning av de akustiska och språkmodeller som ingår i ASR stora mängder brusspecifik data, vilket kan vara tids- och kostnadskrävande.
Den akustiska modellen (AM) förvandlar ord till "telefoner", som är sekvenser av grundläggande ljud. Språkmodellen (LM) avkodar telefoner till naturliga meningar, vanligtvis med en tvåstegsprocess:en snabb men relativt svag LM genererar en uppsättning meningskandidater, och en kraftfull men beräkningsmässigt dyr LM väljer den bästa meningen bland kandidaterna.
"Traditionella inlärningsmodeller är inte robusta mot bullriga akustiska modellutgångar, särskilt för kinesiska polyfoniska ord med identiskt uttal," sa Wu. "Om det första passet av inlärningsmodellavkodningen är felaktig är det extremt svårt för det andra passet att ta igen det."
Det nyligen föreslagna ramverket PSP gör det lättare att återställa felklassificerade ord. Genom att förträna en modell som översätter AM-utgångarna direkt till mening tillsammans med den fullständiga kontextinformationen, kan forskare hjälpa LM att effektivt återhämta sig från AM:s bullriga utsignaler.
PSP-ramverket gör det möjligt för modellen att förbättras genom en förträningsregim som kallas bullermedveten läroplan som gradvis introducerar nya färdigheter, börjar lätt och gradvis går över till mer komplexa uppgifter.
"Den mest avgörande delen av vår föreslagna metod, Noise-aware Curriculum Learning, simulerar mekanismen för hur människor känner igen en mening från bullrigt tal," sa Wu.
Uppvärmning är det första steget, där forskare förtränar en telefon-till-ord-givare på en ren telefonsekvens, som endast översätts från omärkt textdata - för att minska anteckningstiden. Detta steg "värmer upp" modellen och initierar de grundläggande parametrarna för att mappa telefonsekvenser till ord.
I det andra steget, självövervakad inlärning, lär sig givaren från mer komplexa data som genereras av självövervakade träningstekniker och funktioner. Slutligen finjusteras den resulterande telefon-till-ord-omvandlaren med verkliga taldata.
Forskarna demonstrerade experimentellt effektiviteten av deras ramverk på två verkliga datauppsättningar som samlats in från industriella scenarier och syntetiskt brus. Resultaten visade att PSP-ramverket effektivt förbättrar den traditionella ASR-pipelinen, vilket minskar den relativa teckenfelfrekvensen med 28,63 % för den första datamängden och 26,38 % för den andra.
I nästa steg kommer forskare att undersöka mer effektiva PSP-förträningsmetoder med större oparade datauppsättningar, i syfte att maximera effektiviteten av förträning för bullerstark LM. + Utforska vidare